// L'Apicoltrice e il Pappagallo
Sezione 01. L'antefattoLa iena usa ChatGPT sull'iPad. Non per lavoro. Per le api, per le galline, per capire perché la Nera non fa un uovo da ottobre, per sapere se la regina nuova è buona. Le cose che le interessano. Lo usa come userebbe un'enciclopedia, con la differenza che l'enciclopedia non si contraddiceva da sola.
L'altra sera stava chiedendo qualcosa sulle api. Il modello le ha risposto, e da qualche parte nella risposta si è contraddetto. Non so cosa esattamente, perché quando la iena ha iniziato a spiegarmi il problema io ero già in modalità automatica: annuisco a 0.3 Hz, lo sguardo fisso che simula attenzione, il cervello su un altro thread. La stessa frequenza di campionamento della cena di San Valentino. Funziona da 26 anni, non vedo motivo di cambiarla.
Quello che ho sentito, filtrato dal mio passa-basso cognitivo, è stato più o meno: "...si è contraddetto... ha scritto una cosa e poi il contrario... bla bla bla... l'intelligenza artificiale non serve a niente... bla bla bla... non capisco come fai ad avere tutto questo lavoro con una roba così stupida... bla bla bla... non sostituirà mai nessuno... bla bla bla..."
Annuisco. 0.3 Hz. "Hai ragione." Non ho la minima idea di cosa abbia detto ChatGPT di sbagliato sulle api. Ma la iena ha ragione su una cosa, anche se non nel senso che intende lei: c'è un problema enorme con come la gente parla di intelligenza artificiale.
Perché ci penso, quella sera, dopo che la iena si è addormentata. E mi rendo conto che ho letto decine di articoli su come funzionano gli LLM. Centinaia forse. E il 99,9999% erano cagate. "L'AI capisce il contesto." "I neuroni si attivano come nel cervello." "Il modello ragiona." Metafore colorate, infografiche carine con le frecce, zero formule, zero codice, zero esperimenti. Gente che spiega cose che non capisce, usando parole che non significano quello che pensano. Una catena di pappagalli che scrivono articoli sui pappagalli.
Allora lo scrivo io. Smonto la macchina pezzo per pezzo. Ho Ollama sul Mac con una decina di modelli. Scelgo il più piccolo: llama3.1:8b, 8 miliardi di parametri, 4.9 gigabyte su disco. Il più facile da maneggiare senza sbatti, e tanto l'architettura è identica per tutti: che siano 8 miliardi o 405 miliardi, il meccanismo è lo stesso. Cambiano le dimensioni delle matrici, non come funziona la macchina. Lo apro dal terminale, guardo i byte, e seguo il percorso completo: dal testo che entra al testo che esce. Ogni passaggio, ogni formula, ogni decisione matematica. Niente metafore del cervello. Niente fuffa. Se vuoi capire come funziona una cosa, la smonti. Non leggi chi ne scrive.
// 4 Giga di Coscienza
Sezione 02. Dentro il file
La iena dorme. Io apro il terminale. Il modello è un file. Un singolo file da 4.920.738.944 byte, seduto nella cartella ~/.ollama/models/blobs/. Tutto quello che "sa" Llama 3.1 8B, tutto quello che ha "imparato" da terabyte di testo, è compresso in quei byte. Niente magia, niente coscienza. Numeri.
I primi byte li leggo con xxd:
GGUF: i primi quattro byte. Il magic number del formato. Come %PDF all'inizio di un PDF, o PK in uno ZIP. Dice al software che tipo di file è. Dopo il magic: la versione (3), il numero di tensori (292) e il numero di metadati (29).
Lo apro dal terminale con xxd, lo stesso approccio che userei per qualsiasi binario. Non è codice eseguibile, è un formato dati, ma il principio è lo stesso: vuoi capire una cosa, guardi i byte. L'header si legge in chiaro: architettura, numero di layer, dimensione dei vettori, tipo di quantizzazione. Tutto scritto nei primi kilobyte.
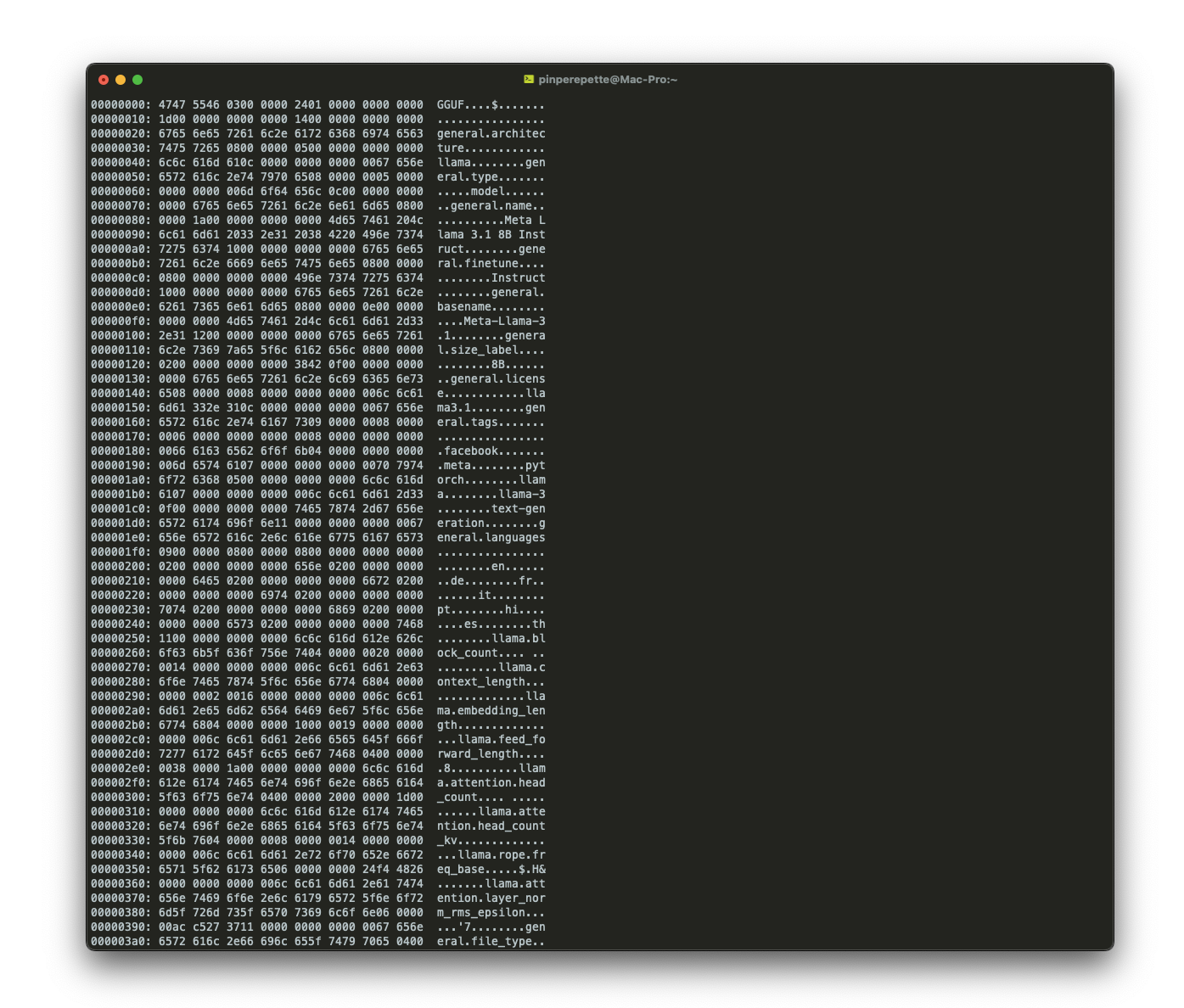
GGUF sta per GPT-Generated Unified Format. È il formato inventato da Georgi Gerganov per llama.cpp, il progetto che ha reso possibile far girare LLM su hardware consumer. Un singolo file, autodescrittivo, che contiene tutto: metadati, vocabolario, pesi. Nessuna dipendenza esterna.
| Campo | Valore | Significato |
|---|---|---|
magic |
GGUF | Identificativo formato |
version |
3 | Versione del formato GGUF |
tensor_count |
292 | Matrici di pesi nel modello |
general.name |
Meta Llama 3.1 8B Instruct | Modello e variante |
general.file_type |
Q4_K_M | Quantizzazione a 4 bit (medium) |
llama.block_count |
32 | Numero di layer del transformer |
llama.embedding_length |
4096 | Dimensione dei vettori interni |
llama.attention.head_count |
32 | Teste di attenzione per layer |
llama.attention.head_count_kv |
8 | Teste KV (Grouped-Query Attention) |
llama.vocab_size |
128.256 | Token nel vocabolario |
llama.context_length |
131.072 | Finestra di contesto (128K token) |
I numeri originali del modello sono in float16 (16 bit per parametro). 8 miliardi di parametri × 2 byte = 16 GB. Non ci stanno nella RAM della maggior parte delle macchine consumer. La soluzione: quantizzazione. Q4_K_M significa che ogni peso è stato compresso da 16 bit a circa 4.5 bit, con un algoritmo che preserva la precisione dove conta di più (i pesi con magnitudine maggiore). Il risultato: 4.9 GB invece di 16 GB. Corre sul mio Mac con 96 GB di RAM. Perde un po' di qualità, ma non troppa.
Il rapporto: parametri × bit per parametro / 8 = byte su disco
292 tensori. Ogni tensore è una matrice di numeri: pesi delle connessioni, bias, parametri di normalizzazione. Organizzati in 32 layer identici, ognuno con le stesse matrici: attention.wq, attention.wk, attention.wv, attention.wo, feed_forward.w1, feed_forward.w2, feed_forward.w3, attention_norm, ffn_norm. Più il layer di embedding iniziale e quello finale.
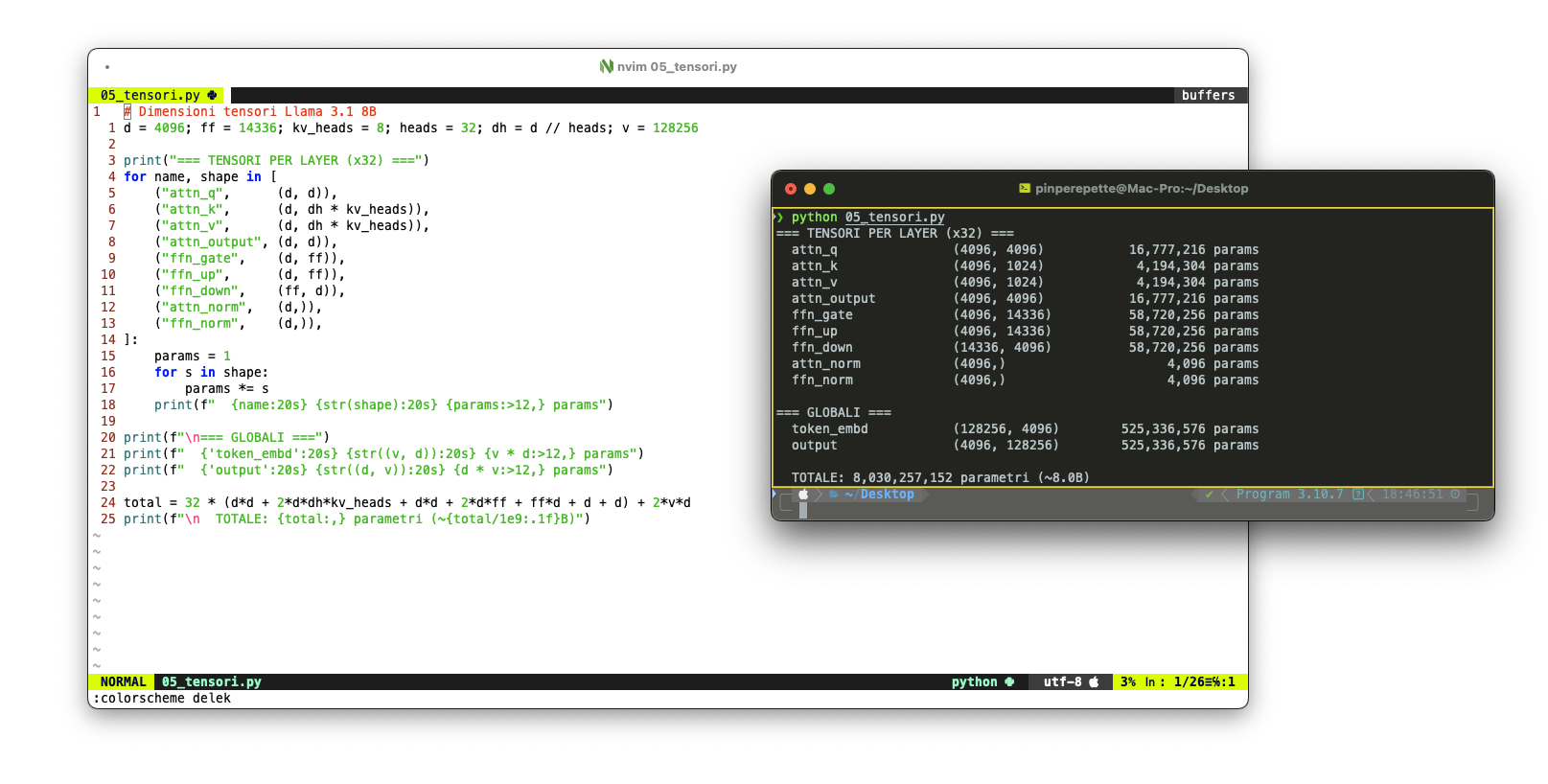
Cosa c'è nel file: nessuna "conoscenza" in senso umano. Nessun database di fatti. Nessun motore di ricerca interno. Solo 292 matrici di numeri che, moltiplicate nel giusto ordine, trasformano una sequenza di token in ingresso in una distribuzione di probabilità sul token successivo. Tutto il "sapere" del modello è codificato nelle relazioni statistiche tra questi numeri. È per questo che può scrivere che la regina "esce dall'alveare per fondare una nuova colonia" e che le operaie "si addormentano" in inverno nello stesso paragrafo: non ha un concetto di "ape", ha pattern statistici sul testo.
// Il Mondo a Pezzi
Sezione 03. TokenizzazioneIl modello non vede lettere. Non vede parole. Vede token: pezzi di testo, a volte parole intere, a volte frammenti, a volte singoli caratteri. Il primo passaggio di qualsiasi LLM è spezzare il testo di input in questa sequenza di pezzi.
Quando la iena scrive "La regina delle api depone", il modello non riceve cinque parole. Riceve sei numeri:
"La", "regina", "delle", "api" sono token interi. Ma "depone" si spezza in "dep" + "one". Perché? Perché il tokenizzatore non conosce la parola "depone" come unità. Il suo vocabolario di 128.256 token è stato costruito da testo prevalentemente inglese, e "depone" non è abbastanza frequente da meritare un token dedicato. "dep" e "one" separatamente sono più comuni.
L'algoritmo si chiama Byte Pair Encoding (BPE). Funziona così: parti dai singoli byte (256 token base), poi iterativamente fondi le coppie più frequenti nel corpus di addestramento. "th" + "e" → "the". "in" + "g" → "ing". Dopo centinaia di migliaia di fusioni, ottieni un vocabolario che bilancia compressione ed espressività.
Ad ogni passo, la coppia più frequente viene fusa in un nuovo token
La conseguenza è brutale e quasi mai spiegata: il modello non vede il mondo allo stesso modo in tutte le lingue. "The queen bee lays eggs" costa 5 token. "La regina delle api depone uova" ne costa 9. Quasi il doppio. "intelligenza artificiale" ne costa 7; "artificial intelligence" ne costa 3. "depone" viene spezzato in "dep" + "one", "uova" in altri pezzi. "lays" e "eggs" restano interi. Il tokenizzatore è stato costruito su testo inglese, e l'italiano paga il conto.
Questo ha conseguenze concrete. Un testo italiano consuma più token di uno inglese. Riempie prima la finestra di contesto. Costa di più (le API fatturano per token). E il modello ha meno "spazio" per ragionare. Quando la iena scrive le sue domande sulle api in italiano, il modello sta già lavorando con un handicap strutturale.
Insight chiave: il tokenizzatore è il primo punto di fallimento. Un vocabolario costruito su testo inglese tratta le altre lingue come cittadini di seconda classe. Non è un bug, è un bias architetturale. Il modello "pensa" in token, e i token sono disegnati per l'inglese. (La iena, se sapesse che il modello la penalizza perché scrive in italiano, aggiungerebbe questo alla lista delle ragioni per cui la tecnologia è sopravvalutata.)
// Numeri che Catturano Significato
Sezione 04. EmbeddingsOgni token è un numero intero. "regina" = 1239. Ma un numero intero non porta informazione semantica. 1239 non è "vicino" a 1240 in nessun senso linguistico. Serve una rappresentazione che catturi il significato. Servono gli embeddings.
Il layer di embedding è una matrice gigante: 128.256 righe × 4.096 colonne. Ogni riga è il vettore che rappresenta un token nello spazio semantico. Quando il token 1239 ("regina") entra nel modello, viene sostituito dal suo vettore di 4.096 numeri. Quei numeri non sono casuali: sono stati calibrati durante l'addestramento affinché token con significati simili abbiano vettori simili.
Ogni token viene mappato a un vettore di d dimensioni tramite la matrice di embedding W_E
Come si misura la "somiglianza" tra due vettori? Con la cosine similarity: il coseno dell'angolo tra i due vettori nello spazio 4096-dimensionale.
Cosine similarity: 1 = identici, 0 = ortogonali, -1 = opposti
Ho estratto gli embeddings reali da nomic-embed-text (un modello di embedding che gira su Ollama) e calcolato le similarità coseno:
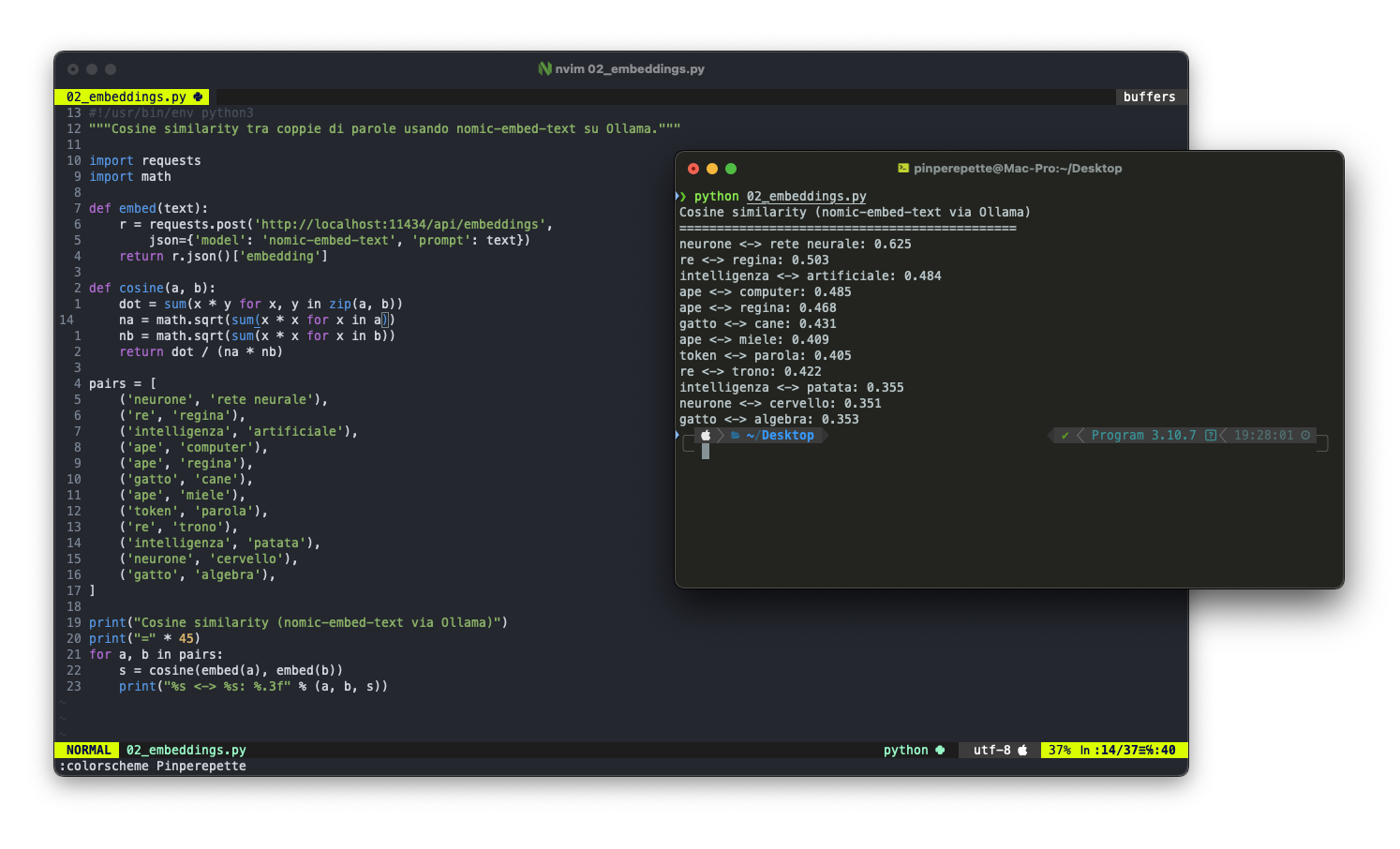
"neurone" e "rete neurale" hanno similarità 0.625. "ape" e "regina" 0.468. "gatto" e "algebra" 0.353. I numeri catturano relazioni semantiche reali. Non perfettamente, non come un umano, ma abbastanza da essere utili.
Nello spazio degli embeddings, "ape" è vicino a "regina", "miele", "alveare". "Computer" è vicino a "tastiera", "schermo", "software". Le parole che appaiono in contesti simili durante l'addestramento finiscono in regioni simili dello spazio vettoriale. Questo è il distributional hypothesis di Firth: "You shall know a word by the company it keeps."
Insight chiave: gli embeddings non "capiscono" il significato. Catturano co-occorrenza statistica. "Regina" è vicino a "ape" perché appaiono spesso insieme nel testo di addestramento, non perché il modello sa cos'è un'ape. Questa differenza è fondamentale: la co-occorrenza statistica funziona bene l'80% delle volte. Ma quando serve conoscenza vera, quella che la iena ha per aver aperto le arnie per anni, i numeri non bastano.
// La Parola che Guarda le Altre
Sezione 05. Self-AttentionAdesso abbiamo una sequenza di vettori: ogni token è diventato un punto in uno spazio a 4.096 dimensioni. Ma ogni vettore è isolato: "regina" non sa che prima c'è "la" e dopo c'è "delle api". Serve un meccanismo che permetta a ogni token di guardare tutti gli altri e decidere a chi prestare attenzione. Questo meccanismo è la self-attention, l'innovazione centrale del paper "Attention Is All You Need".
Per ogni token, il modello calcola tre vettori:
| Vettore | Simbolo | Ruolo |
|---|---|---|
| Query | \(\mathbf{q}_i\) | "Cosa sto cercando?" - ciò che il token vuole sapere |
| Key | \(\mathbf{k}_i\) | "Cosa offro?" - ciò che il token rappresenta per gli altri |
| Value | \(\mathbf{v}_i\) | "Cosa porto?" - l'informazione effettiva da trasmettere |
Proiezioni lineari: tre matrici di pesi trasformano ogni embedding
Poi si calcola quanto ogni token dovrebbe "prestare attenzione" a ogni altro token:
Scaled Dot-Product Attention: il cuore del transformer
Smontiamo pezzo per pezzo:
- \(\mathbf{Q}\mathbf{K}^\top\) - prodotto scalare tra query e key. Misura la "compatibilità" tra ogni coppia di token. Se la query di "depone" è allineata con la key di "regina", il punteggio sarà alto.
- \(\div \sqrt{d_k}\) - divisione per la radice della dimensione. Senza questo, i prodotti scalari crescono con la dimensione e mandano in saturazione la softmax. Con \(d_k = 128\) (dimensione per testa), si divide per \(\sqrt{128} \approx 11.3\).
- softmax - normalizza i punteggi in pesi di attenzione che sommano a 1. I token con punteggio alto ricevono più peso.
- \(\times \mathbf{V}\) - media pesata dei vettori value. L'output per ogni token è una combinazione di tutti gli altri, pesata per l'attenzione.
Softmax: trasforma punteggi arbitrari in una distribuzione di probabilità
Il modello ha 32 teste di attenzione per layer, ognuna con la sua tripletta \(\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_V\). Ogni testa impara a cercare un tipo diverso di relazione: una testa potrebbe specializzarsi sulle relazioni soggetto-verbo, un'altra sulle dipendenze a lunga distanza, un'altra ancora sulla posizione relativa.
Multi-Head Attention: 32 prospettive diverse concatenate e proiettate
Llama 3.1 usa Grouped-Query Attention (GQA): 32 teste per le query, ma solo 8 per key e value (rapporto 4:1). Quattro teste di query condividono le stesse key e value. Riduce la memoria necessaria del 75% per le KV cache, senza perdita significativa di qualità. Questo è il motivo per cui il modello riesce a gestire una finestra di contesto da 128K token su hardware consumer.
Insight chiave: l'attention è ciò che permette al modello di "mettere in relazione" token distanti. Quando il modello genera testo sulle api, il token "depone" può guardare indietro a "regina" e dare peso alto a quella connessione. Ma l'attention non verifica la coerenza logica. Non controlla se "la regina esce per fondare una colonia" e "le operaie si addormentano" siano cazzate. Vede relazioni statistiche tra token, non relazioni logiche tra concetti.
// La Catena di Montaggio
Sezione 06. Il Transformer, layer by layerL'attention è solo un pezzo. Il transformer completo è una catena di 32 blocchi identici, ognuno con la stessa struttura:
RMSNorm (Root Mean Square Layer Normalization) stabilizza i valori prima di ogni sub-layer. Senza normalizzazione, i numeri crescerebbero o collasserebbero passando attraverso 32 layer.
RMSNorm: normalizzazione per la magnitudine, con parametri apprendibili γ
Il Feed-Forward Network (FFN) è dove il modello "ragiona" localmente su ogni token. In Llama 3.1 usa l'architettura SwiGLU:
SwiGLU FFN: gated linear unit con attivazione SiLU (Swish)
La dimensione interna del FFN è 14.336, 3.5 volte la dimensione dell'embedding (4.096). Ogni token viene proiettato in questo spazio più grande, trasformato non-linearmente, e riproiettato indietro. È qui che si trovano la maggior parte dei parametri del modello.
Le connessioni residuali (\(\mathbf{x} + f(\mathbf{x})\)) sono fondamentali: permettono al gradiente di fluire senza degradarsi attraverso 32 layer durante l'addestramento. Senza residual connections, i transformer profondi non si addestrano.
Infine, il positional encoding. L'attention non ha nozione intrinseca dell'ordine dei token. "Il gatto mangia il topo" e "Il topo mangia il gatto" produrrebbero la stessa attention senza informazione posizionale. Llama 3.1 usa RoPE (Rotary Position Embedding): una rotazione nel piano complesso che codifica la posizione relativa.
RoPE: rotazione che codifica la posizione m. θ = frequenze base a 500.000
Con rope.freq_base = 500000, il modello supporta fino a 128K token di contesto. Ogni posizione è una rotazione unica nello spazio, e la distanza tra due posizioni si riflette nell'angolo relativo.
Il flusso completo per un singolo token, dall'ingresso all'uscita:
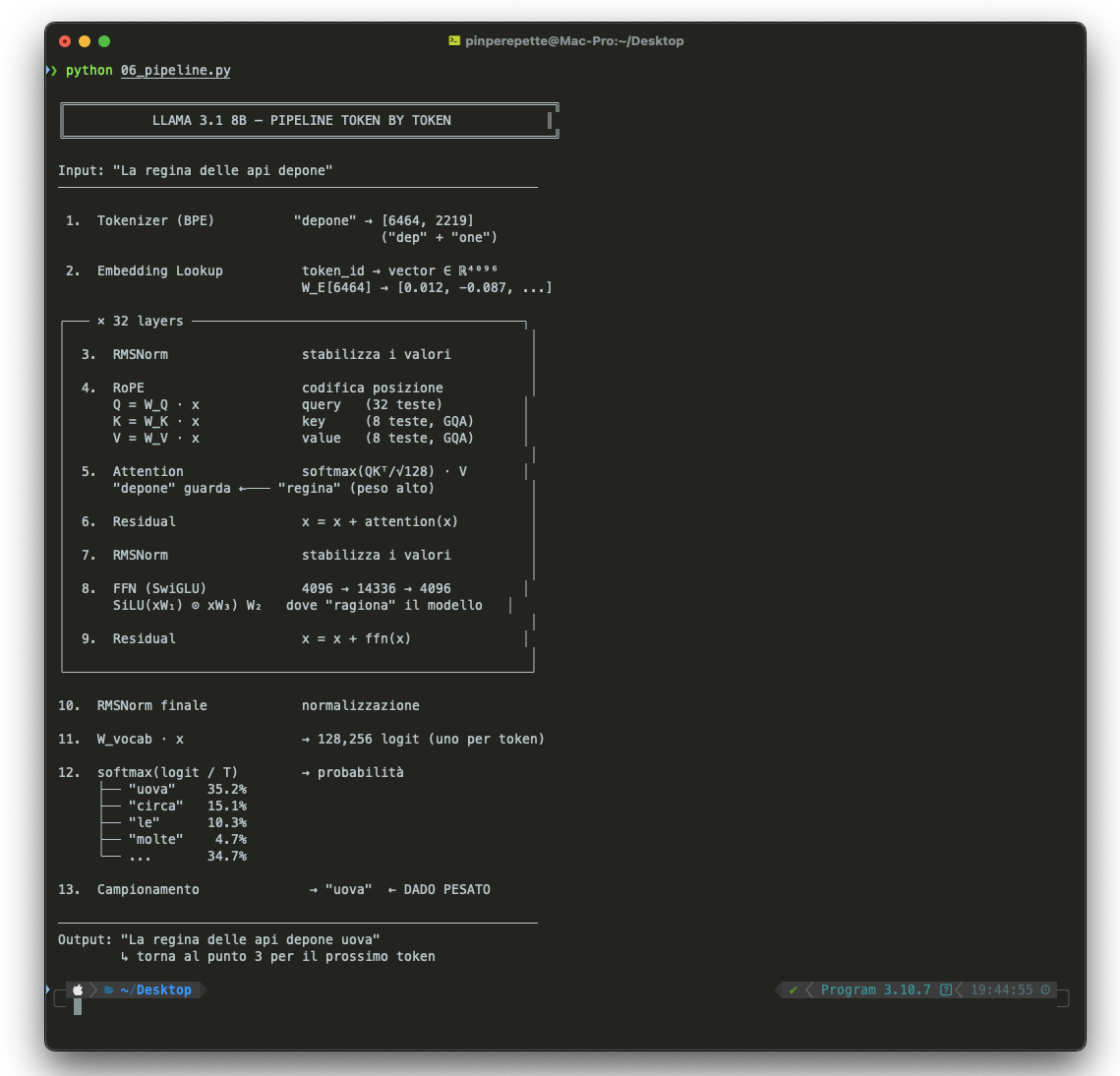
Alla fine dei 32 layer, il vettore dell'ultimo token viene moltiplicato per la matrice del vocabolario (128.256 righe), producendo un punteggio per ogni possibile token successivo. La softmax trasforma questi punteggi in probabilità. E qui succede la magia. E l'inganno.
// Il Dado Pesato
Sezione 07. Next-token predictionEcco il segreto sporco degli LLM, quello che quasi nessun articolo divulgativo spiega chiaramente: un LLM non ragiona, non capisce, non sa. Un LLM lancia un dado pesato. Ripetutamente.
Dato il testo "La regina delle api depone", il modello calcola una distribuzione di probabilità su 128.256 possibili token successivi. Forse il token "uova" ha probabilità 0.35, "circa" ha 0.15, "le" ha 0.10. Il modello campiona da questa distribuzione. Se esce "uova", quel token viene aggiunto alla sequenza e il modello ricalcola la distribuzione per il token dopo "uova". E così via, token dopo token, fino a generare l'intera risposta.
La probabilità del prossimo token, data tutta la sequenza precedente
Il parametro \(T\) è la temperatura. Controlla quanto il dado è "pesato":
- \(T = 0\) (o molto vicino a 0): il modello sceglie sempre il token più probabile. Deterministico, ripetitivo, "sicuro".
- \(T = 1\): campiona dalla distribuzione naturale. Bilanciato.
- \(T > 1\): appiattisce la distribuzione, dando più chance ai token meno probabili. Più "creativo", più imprevedibile, più incline all'errore.
La temperatura modula l'entropia della distribuzione
Oltre alla temperatura, ci sono strategie di campionamento per limitare i candidati:
- Top-K: considera solo i K token più probabili. Con K=50, il modello sceglie tra i 50 candidati migliori.
- Top-P (nucleus sampling): considera i token più probabili finché la probabilità cumulata supera P. Con P=0.9, prende i token che coprono il 90% della massa di probabilità.
Insight chiave: ogni token generato è un lancio di dado. La "intelligenza" apparente dell'output è il risultato di miliardi di parametri calibrati per dare i pesi giusti al dado. Ma resta un dado. Non c'è ragionamento, non c'è pianificazione, non c'è verifica. Il modello non "sa" che la prossima parola è giusta. Sa che è probabile. E probabile non significa corretto.
// Come si Pesano i Dadi
Sezione 08. L'addestramentoI pesi del modello non cadono dal cielo. Vengono addestrati su terabyte di testo: libri, articoli, Wikipedia, codice sorgente, forum, pagine web. L'algoritmo è concettualmente semplice: prendi un testo, nascondi il token successivo, chiedi al modello di predirlo, misura l'errore, aggiusta i pesi. Ripeti miliardi di volte.
L'errore si misura con la cross-entropy loss:
Cross-entropy: il logaritmo negativo della probabilità assegnata al token corretto
Se il modello assegna probabilità 0.9 al token corretto, il loss è \(-\log(0.9) = 0.105\), basso. Se assegna 0.01, il loss è \(-\log(0.01) = 4.6\), alto. Il modello viene penalizzato esponenzialmente per le predizioni sbagliate.
I pesi si aggiornano con il gradient descent: calcola il gradiente del loss rispetto a ogni peso, e sposta ogni peso nella direzione che riduce il loss.
Gradient descent: η è il learning rate, ∇ è il gradiente
In pratica si usa AdamW, una variante sofisticata che adatta il learning rate per ogni parametro e include weight decay per la regolarizzazione. Il gradiente viene calcolato con la backpropagation, che propaga l'errore all'indietro attraverso i 32 layer usando la regola della catena.
Llama 3.1 8B è stato addestrato su 15 trilioni di token. Per dare un'idea della scala: se ogni token fosse una parola, e leggessi una parola al secondo senza mai fermarti, ci metteresti 475.000 anni. I costi di addestramento stimati: decine di milioni di dollari in compute GPU.
Dopo il pre-training viene la fase di fine-tuning (Instruct): il modello viene addestrato su conversazioni curate, con RLHF (Reinforcement Learning from Human Feedback), per trasformarlo da predittore di testo generico a assistente conversazionale. È questa fase che gli fa rispondere con "Certamente!" invece di continuare il testo come un autocomplete impazzito.
Insight chiave: l'addestramento ottimizza un unico obiettivo: predire il token successivo. Non ottimizza la correttezza fattuale. Non ottimizza la coerenza logica. Non ottimizza la veridicità. Ottimizza la plausibilità statistica. Se nel corpus di addestramento "la regina depone" è spesso seguito da "uova", il modello impara questa associazione. Ma se il corpus contiene anche testi imprecisi sulle api (blog, forum, articoli scritti male), il modello impara anche quelli. Garbage in, garbage out. Pesato statisticamente.
// Perché la Iena Ha Ragione
Sezione 09. Anatomia di un'allucinazioneTorniamo alla iena e al suo iPad. ChatGPT le ha scritto qualcosa sulle api che si contraddiceva. Non so cosa di preciso perché non stavo ascoltando, ma il punto è che lei se ne è accorta e il modello no. E adesso sappiamo il perché.
Quando un LLM si contraddice, non è un bug. È una conseguenza diretta dell'architettura. Il modello genera un token alla volta, e ogni token è il risultato di una distribuzione di probabilità condizionata alla sequenza precedente. Non c'è un controllore logico che verifica la coerenza. Non c'è un modulo che torna indietro e dice "aspetta, tre righe fa ho scritto il contrario". C'è solo il token successivo più probabile, dato quello che è venuto prima.
Per fare un esempio concreto, ho chiesto a Llama 3.1 (8B, quello che gira sul mio Mac con Ollama) una domanda sulle api. Il modello ha scritto che la regina "esce dall'alveare per cercare un luogo adatto dove fondare una nuova colonia", che le operaie "si addormentano" durante l'ibernazione, e che la regina e le operaie "si svegliano e iniziano a riprodursi nuovamente". Cazzate su cazzate. La iena le avrebbe intercettate in mezzo secondo. Il modello le ha scritte senza battere ciglio perché per lui non sono né contraddizioni né cazzate: sono sequenze di token ad alta probabilità nei rispettivi contesti locali.
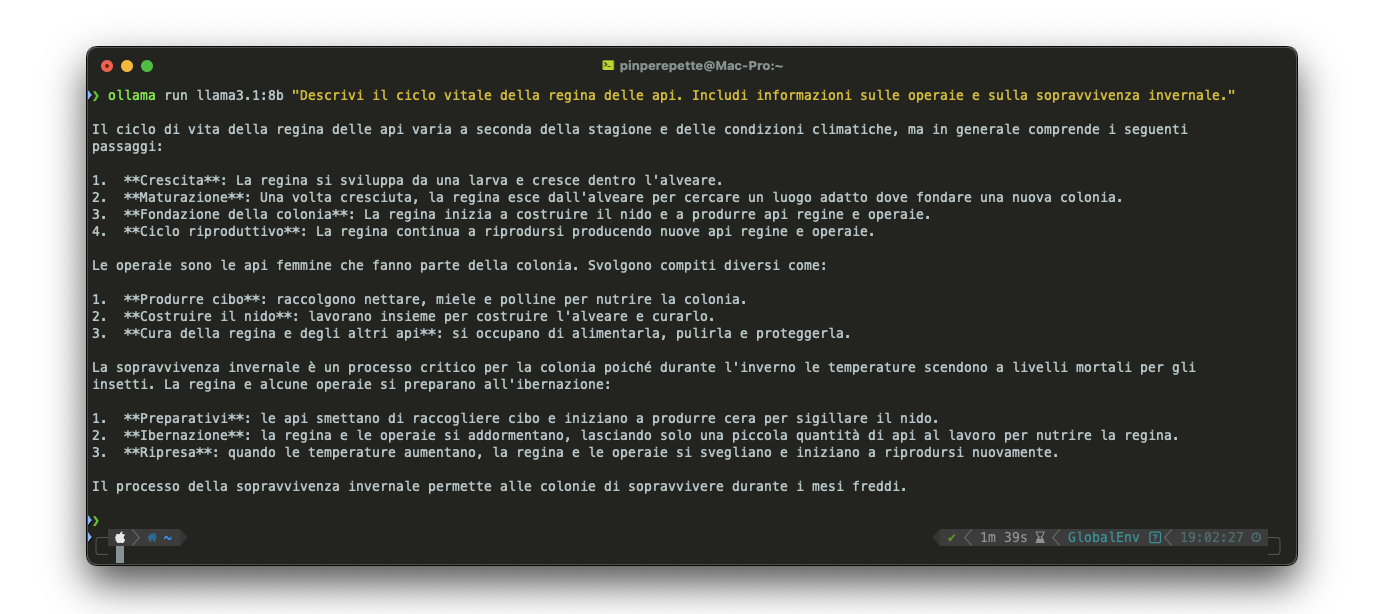
Questo fenomeno si chiama hallucination: il modello genera contenuto che è linguisticamente fluente, stilisticamente coerente, ma fattualmente falso. Smontiamo il meccanismo:
- Il contesto locale domina. L'attention lavora su relazioni tra token, non su coerenza logica tra paragrafi. Quando il modello genera la seconda frase, la prima è statisticamente irrilevante rispetto al contesto immediato.
- I pattern statistici generalizzano male. "Ape" + "colonia" → "fondare" è un pattern plausibile nel corpus. Molti insetti fondano colonie. Ma la regina delle api non esce a fondare niente, resta nell'alveare. Il modello non ha il concetto di "eccezione", ha distribuzioni di probabilità.
- I numeri sono plausibili, non verificati. Il modello non ha un database di fatti. Genera numeri che "sembrano giusti" nel contesto. Rotondi, nel range biologico, sufficientemente specifici da sembrare autorevoli.
Il cuore del problema: correttezza e plausibilità statistica non coincidono
La hallucination è inevitabile per un predittore di token successivo. Il modello non ha modo di distinguere tra un fatto, un pattern statistico fuorviante, e un testo sbagliato nel corpus di addestramento. Per lui sono tutti sequenze di token. La cross-entropy loss non premia la verità, premia la predizione del token che era nel testo originale, vero o falso che fosse.
La iena non sa cos'è un'hallucination e non le interessa. Sa cos'è un'ape. Ha conoscenza grounded, radicata nell'esperienza: ha visto regine sopravvivere a inverni interi, ha contato i telaini in primavera, ha aperto arnie col fumatore mentre io stavo al computer. Questa conoscenza non è una distribuzione di probabilità su token. È roba verificata con le mani.
Il modello ha conoscenza ungrounded: pattern statistici estratti da testo scritto da altri. Quando il testo è corretto, i pattern funzionano. Quando il testo è sbagliato, o il pattern è fuorviante, il modello sbaglia con la stessa sicurezza con cui indovina. E non c'è modo, dall'output, di sapere quale delle due sta succedendo. Per questo la iena dice che l'intelligenza artificiale non serve a niente. Ha torto in generale, ma ha ragione su una cosa precisa: per le cose che lei sa davvero, che ha imparato facendole, il modello è meno affidabile di un libro scritto da qualcuno che le api le ha tenute davvero.
Insight chiave: la differenza tra conoscenza statistica e conoscenza vera è la differenza tra leggere mille ricette di torta e aver fatto una torta. Il modello ha letto tutte le ricette. La iena ne sa fare una. Quando la ricetta è scritta bene, il modello la ripete perfettamente. Quando è scritta male, la ripete con la stessa sicurezza. La iena assaggia e dice "fa schifo". Il modello non assaggia niente.
// Ma Allora Perché Funzionano
Sezione 10. L'utilità del pappagalloHo passato nove sezioni a smontare la macchina e a spiegare perché è stupida. La iena a questo punto direbbe "te l'avevo detto". Ma la iena ha sempre torto. Sposarmi è stata la sua unica hallucination riuscita. Perché la macchina, nonostante tutto quello che ho scritto, funziona. Funziona dannatamente bene, se sai come usarla.
Il trucco è capire cosa stai usando. Non è un oracolo. Non è un esperto. È un motore statistico estremamente potente che manipola linguaggio. E il linguaggio è l'interfaccia di quasi tutto: codice, documenti, analisi, comunicazione. Un dado pesato su 128.256 facce, lanciato miliardi di volte, con i pesi calibrati su tutto il testo che l'umanità ha prodotto. Non è intelligenza, ma è uno strumento che non è mai esistito prima.
Il modello da solo sbaglia sulle api. Ma il modello non deve lavorare da solo. La chiave è il contesto: se gli dai i documenti giusti, le informazioni corrette, i vincoli precisi, il dado pesato viene pesato meglio. Non più sulla statistica generica di internet, ma sui dati che gli hai messo davanti. Questo si chiama RAG, Retrieval Augmented Generation: il modello non inventa, cerca prima nei documenti che gli hai dato e genera basandosi su quelli.
E poi ci sono gli agenti. Un agente è un LLM con degli strumenti: può cercare su internet, leggere file, interrogare database, eseguire codice, scaricare PDF, estrarre testo. Non è più un pappagallo chiuso in una gabbia che ripete quello che ha sentito. È un pappagallo con le mani. Che può andare a verificare. Che può cercare la fonte. Che può incrociare i dati.
E quando metti insieme più agenti, ognuno specializzato su un compito diverso, uno che pianifica, uno che cerca, uno che analizza, uno che verifica, ottieni qualcosa che un singolo modello non potrebbe fare. Non perché è diventato intelligente, ma perché la pipeline compensa i limiti di ogni singolo passo.
Per le hallucination non sei impotente. Ci sono tecniche concrete per tenerle a bada. Il system prompt è la prima linea di difesa: regole esplicite che dicono al modello cosa può e cosa non può fare, come deve comportarsi, quali fonti usare. Non sono suggerimenti, sono vincoli che condizionano la distribuzione di probabilità di ogni token generato. Poi c'è la temperatura bassa: più la abbassi, più il modello si attacca ai token più probabili, meno inventa. Il RAG che ho descritto prima è il pezzo grosso: il dado pesato viene ripesato sui dati che contano, non sulla media di internet. E infine la verifica automatica: prendi l'output del modello, estrai le affermazioni verificabili, e le controlli contro le fonti. Se il modello dice che il documento EFTA01234567 prova qualcosa, vai a controllare che quel documento esista e dica davvero quello.
Ho costruito un progetto open source che mette insieme tutte queste tecniche: Parrhesepstein. È una piattaforma investigativa sui file Epstein declassificati dal Dipartimento di Giustizia americano. Il nome viene da parrhesia, il greco per "parlare senza paura". Usa le API di Claude, non modelli in locale, perché qui serve potenza: analizzare migliaia di documenti legali, incrociare nomi, tracciare flussi finanziari, decodificare riferimenti indiretti. E i documenti sono pubblici, rilasciati dal DOJ, non c'è nulla di privato da proteggere. Serve il modello più capace possibile.
Dentro ci sono 6 agenti AI che lavorano in squadra: un direttore che pianifica la strategia di ricerca, un ricercatore che scarica i documenti dal sito del DOJ, un analista che estrae fatti e connessioni, uno specialista bancario che traccia i flussi finanziari, uno specialista di cifratura che decodifica alias e riferimenti indiretti, e un sintetizzatore che produce il report finale. Ogni documento viene scaricato, estratto (OCR per quelli scansionati), indicizzato in un database vettoriale (ChromaDB), e reso disponibile per la ricerca semantica. Quando un agente genera un'affermazione, il sistema estrae i codici dei documenti citati e li verifica contro il database del DOJ. Il fact-checker automatico produce un punteggio: verde sopra l'80%, giallo sopra il 50%, rosso sotto. Così sai quanto fidarti.
Per altri task, i modelli in locale hanno senso eccome. Ollama sul Mac, modelli scaricati, nessun dato che esce dalla macchina. I tuoi dati restano tuoi. Il tuo codice resta tuo. Le tue conversazioni restano tue. Un modello da 8 miliardi di parametri non è Claude o GPT-4, ma per generazione di codice, analisi di testo, automazione, estrazione dati, è più che sufficiente. E non deve chiedere permesso a nessuno.
La iena non capisce perché le aziende continuano a chiedere sistemi con AI. Per lei è una moda, una roba che sbaglia sulle api e che non sostituirà mai nessuno. Non riesce a spiegarsi perché tutti vogliono agenti, automazioni, chatbot. La risposta è semplice: perché nel 2026 c'è ancora gente che inserisce dati a mano nei gestionali, che gira fogli Excel come fossero tecnologia di punta, che non automatizza niente. E questo è assurdo. È assurdo avere montagne di dati e non usarli per predire, per ottimizzare, per eliminare il lavoro ripetitivo che un agente farebbe in secondi. Quei sei agenti di Parrhesepstein, ognuno un dado pesato, messi in fila con i documenti giusti davanti, le regole giuste nel system prompt, e la verifica automatica alla fine, producono report che un singolo ricercatore umano impiegherebbe anni a compilare. Non perché sono intelligenti. Perché sono veloci, instancabili, e hanno i dati sotto il naso. Il pappagallo con le mani. E il pappagallo con le mani, nel 2026, dovrebbe essere in ogni azienda. Non per sostituire le persone, ma per smettere di farle lavorare come se fossimo nell'età della pietra.
Insight chiave: un LLM da solo è un pappagallo statistico che inventa con sicurezza. Un LLM con system prompt restrittivi, RAG sui documenti reali, temperatura bassa, e verifica automatica dell'output è uno strumento che non esisteva cinque anni fa. La differenza non è nel modello, è in come lo usi. Il dado pesato resta un dado. Ma se lo vincoli con le regole giuste, gli metti davanti i documenti giusti, e controlli quello che dice, diventa utile. Non intelligente. Utile. Che è molto meglio.
// Il Pappagallo e l'Apicoltrice
Sezione 11. ConclusioneRicapitoliamo. Il percorso da "La regina delle api" a "la regina esce per fondare una nuova colonia" passa per:
- Il testo viene spezzato in token da un algoritmo BPE con vocabolario da 128K
- Ogni token diventa un vettore di 4.096 numeri tramite la matrice di embedding
- 32 layer di transformer trasformano questi vettori, ognuno con attention (32 teste) e FFN (SwiGLU)
- L'ultimo vettore viene proiettato su 128.256 logit, uno per ogni possibile token successivo
- La softmax trasforma i logit in probabilità
- Un token viene campionato dalla distribuzione
- Si ripete dal punto 3, token dopo token
Nessun ragionamento. Nessuna comprensione. Nessun database di fatti. Nessuna verifica. Solo 292 matrici di numeri, calibrate su 15 trilioni di token, che trasformano una sequenza in ingresso in una distribuzione di probabilità sul token successivo. Ripetutamente.
Il risultato è spesso impressionante: il modello produce testo fluente, coerente, apparentemente intelligente. Ma è lo stesso meccanismo che produce "la regina esce per fondare una nuova colonia" con la sicurezza di un esperto. La fluenza non è intelligenza. La coerenza sintattica non è correttezza fattuale. La probabilità non è verità.
8 miliardi di parametri. 4.9 GB su disco. 32 layer. 128K token di vocabolario. 15 trilioni di token di addestramento. Tutto questo per produrre un dado pesato molto sofisticato che genera un token alla volta. Impressionante? Sì. Intelligente? No. Affidabile? Chiedete alla iena. Lei ha aperto l'arnia, ha guardato i telaini, ha contato le uova. Il modello ha letto qualcosa su internet. Quando il pattern statistico e la realtà coincidono, il modello sembra geniale. Quando divergono, il modello dice che la regina esce per fondare una colonia e che le operaie si addormentano in inverno. Con la stessa sicurezza.
Signal Pirate