// La Notizia
Sezione 00. Cosa è successo questa settimanaNegli ultimi giorni X ha iniziato a rilasciare la traduzione automatica in tempo reale nel feed. Non più il tasto "Traduci post". Non più Google Translate aperto in un'altra tab. Il contenuto viene tradotto direttamente mentre scorri, in silenzio, senza che tu faccia niente. Grok, il modello di X, lavora in background e ti consegna già il testo in italiano.
Sembra una feature di comodità. Un'ottimizzazione UX. Non devi più cliccare. Ma c'è qualcosa sotto che vale la pena capire.
Per capire cosa è cambiato davvero bisogna separare due cose che fino a ieri stavano appiccicate: il motore di raccomandazione e il filtro linguistico sull'output. Erano due sistemi distinti, e X ne ha toccato solo uno.
Il motore di raccomandazione era già semantico, già cross-lingual, già cieco alle lingue. Prendeva un tweet in arabo, lo trasformava in vettore, misurava la distanza dal tuo profilo e decideva se mostrartelo. La lingua non è la dimensione dominante nel calcolo semantico: il sistema lavora principalmente sulla similarità tra rappresentazioni vettoriali. Questo non è cambiato.
Quello che esisteva sopra era un filtro: X preferiva mostrarti contenuti nella tua lingua. Non perché il modello lo richiedesse, ma per ridurre l'attrito dell'utente. Se non capisci il cinese, il tweet in cinese ti disturba. Quindi veniva tenuto indietro. Il motore lo valutava rilevante, ma il filtro linguistico lo frenava.
Ora quel freno è tolto. Il motore gira esattamente come prima. Ma tutto quello che trova rilevante arriva, in qualsiasi lingua, già tradotto. Lo spazio semantico globale è finalmente esposto per intero.
Prima: motore semantico + filtro lingua in output
Ora: motore semantico + nessun filtro + traduzione automatica
Hanno rimosso il tappo. Il motore girava già. Adesso esce tutto.
// La Iena e il Tweet in Cinese
Sezione 01. Il problema spiegato maleSto scrollando il telefono. La iena mi spia con la coda dell'occhio, come fa sempre quando pensa che io stia guardando roba che non devo. Poi vede che sto guardando un tweet in cinese, già tradotto senza che io abbia fatto niente, e decide che è il momento buono.
"Ma quello è cinese."
"Sì, ma X me lo ha già tradotto."
"Lo so. Ma perché te lo propone? Segui cinesi?"
"No."
"Allora perché?"
Risposta automatica: "Perché parla di cose vicine a quello che mi interessa." Lei mi guarda. Io guardo il telefono. Poi mi rendo conto che ho usato la parola sbagliata. Vicine. Vicine come? È una metafora o qualcosa di più preciso? La iena ha il fiuto per queste cose.
"Vicine come, scusa?"
Ecco. Ci siamo.
Il 19 aprile 2026 ho catturato il mio feed di X, 1245 tweet, prima che la notizia della traduzione automatica diventasse rumore sui social. Ho pulito le pubblicità dal database, fatto girare un modello di embedding multilingue su tutto, e misurato. Quello che segue è la risposta alla domanda della iena.
// La Traduzione È Solo la Superficie
Sezione 02. Cosa c'è sottoUn sistema di ranking moderno basato su embedding funziona così: non lavora sul testo grezzo, lavora su vettori. Prima di mostrarti un contenuto, il sistema lo ha già trasformato in un punto nello spazio matematico. La distanza tra quel punto e il tuo profilo determina se lo vedi o no. La lingua del testo originale non è la dimensione dominante nel calcolo: il sistema lavora principalmente sulla similarità tra rappresentazioni vettoriali. Questa analisi non accede al sistema interno di X, ma mostra che il comportamento osservato è coerente con un sistema di ranking basato su embedding semantici. Il codice sorgente parziale del motore di raccomandazione di X pubblicato nel 2023 è allineato con questa architettura.
Quello che è cambiato non è il motore. È il rubinetto. Prima il motore trovava contenuto rilevante in tutte le lingue, ma un filtro sull'output decideva di mostrarti prevalentemente la tua lingua. Meno attrito per l'utente medio, meno valore per chi sa usare il feed. Ora quel filtro è sparito: un sistema di ranking vettoriale lavora come sempre, ma tutto quello che trova rilevante arriva da te, già tradotto da Grok in tempo reale.
Il risultato è che per la prima volta il feed riflette la struttura dello spazio semantico sottostante in modo più diretto. Niente più attenuazione linguistica. Se un tweet in giapponese è vicino al tuo profilo vettoriale, lo vedi. E lo capisci.
Punto chiave. Un sistema di ranking vettoriale era già cross-lingual per costruzione. Il filtro linguistico sull'output attenuava il segnale. Ora quel filtro è rimosso e la traduzione automatica copre l'attrito residuo.
// Cosa È un Vettore
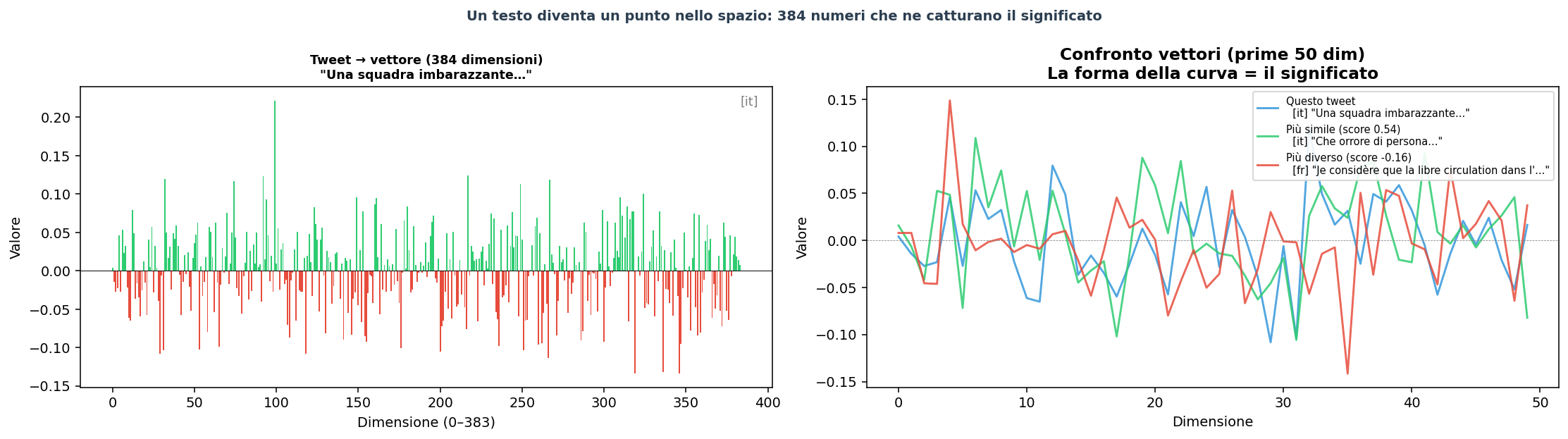
Sezione 03. La matematica sottoUn tweet è testo. Un modello di embedding lo trasforma in un vettore: una lista di numeri. Nel modello che ho usato, 384 numeri.
Ogni numero rappresenta una coordinata in uno spazio a 384 dimensioni. Non riusciamo a visualizzarlo (tre dimensioni sono già il nostro limite), ma matematicamente funziona come lo spazio fisico: due punti vicini si assomigliano, due punti lontani no.
1.0 = identici · 0.0 = non correlati · −1.0 = opposti
La cosa importante è che questo spazio cattura il significato, non le parole. "Cane" in italiano e "dog" in inglese finiscono nella stessa zona. "Guerra" e "conflict" pure. "Putin" e "Kremlin" sono vicini anche se non condividono nessuna lettera.
Il modello che ho usato, paraphrase-multilingual-MiniLM-L12-v2, è stato addestrato su 50 lingue in parallelo, con l'obiettivo esplicito di far sì che la stessa frase in lingue diverse finisca nello stesso punto. È progettato per quello. La lingua diventa un accidente superficiale.
// La Prova Cross-Linguale
Sezione 04. Stesso significato, lingue diverseSmontare il concetto è una cosa. Dimostrarlo sui dati reali è un'altra. Ho preso 1143 tweet dal mio feed (italiano, inglese, arabo, cinese, giapponese, turco, una ventina di lingue in totale) e ho calcolato la similarità coseno tra tutte le coppie possibili, raggruppando per lingua.
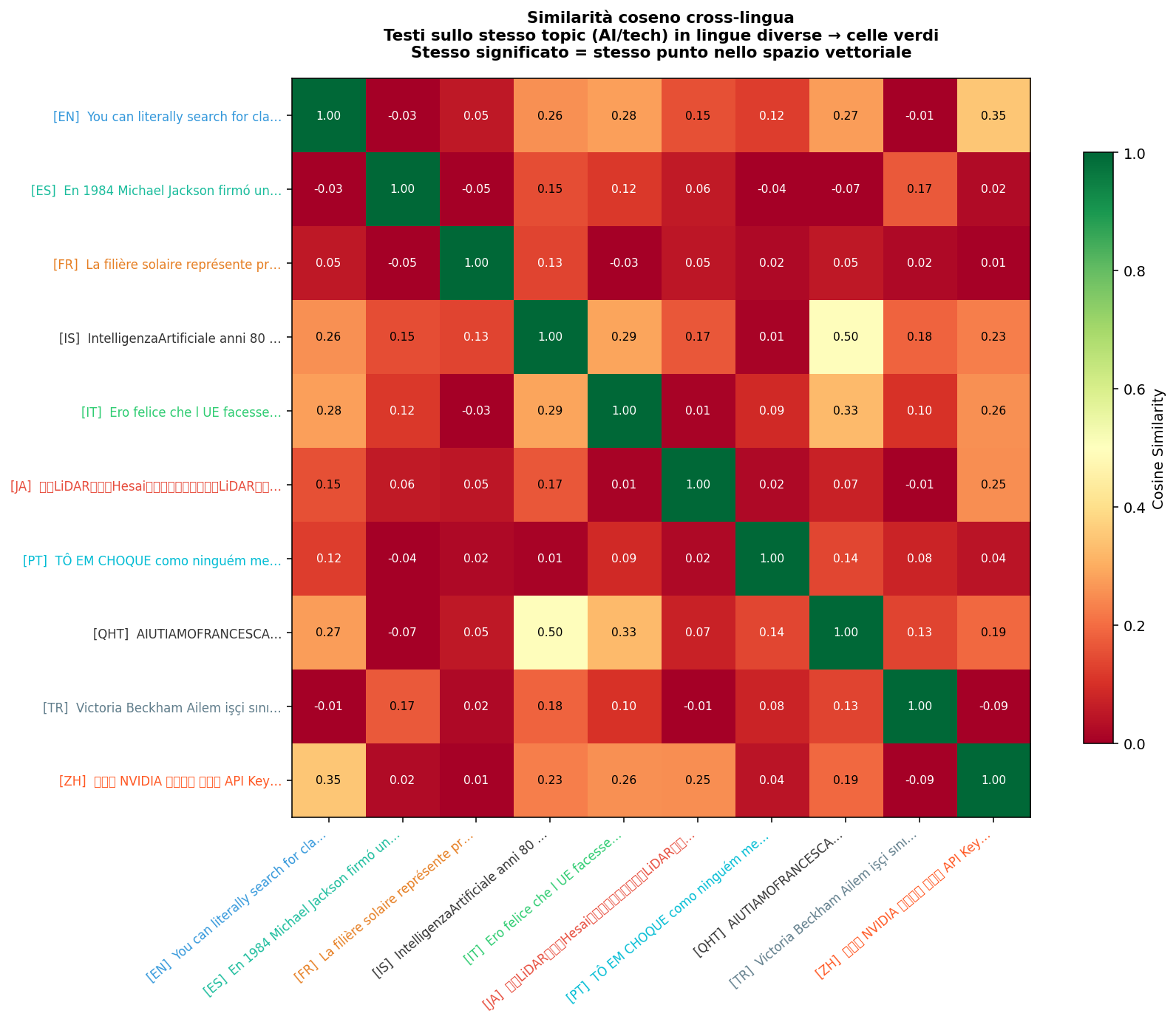
Quello che vedi nella heatmap non è un artefatto del modello. È la struttura del mio feed. Le lingue che appaiono vicine parlano degli stessi argomenti. Il fatto che un tweet in arabo e uno in italiano finiscano nella stessa zona dello spazio significa che il modello ha imparato qualcosa di reale: la struttura del significato è condivisa tra le lingue, non appartiene a nessuna di esse.
Per renderlo ancora più concreto: ho fatto una ricerca semantica cross-linguale. Ho preso una query in italiano, "intelligenza artificiale e sicurezza informatica", e ho cercato i tweet più simili nel feed, indipendentemente dalla lingua. I risultati più vicini includono tweet in inglese, cinese e arabo che parlano esattamente di quello. Nessuna traduzione in input, nessun filtraggio per lingua.
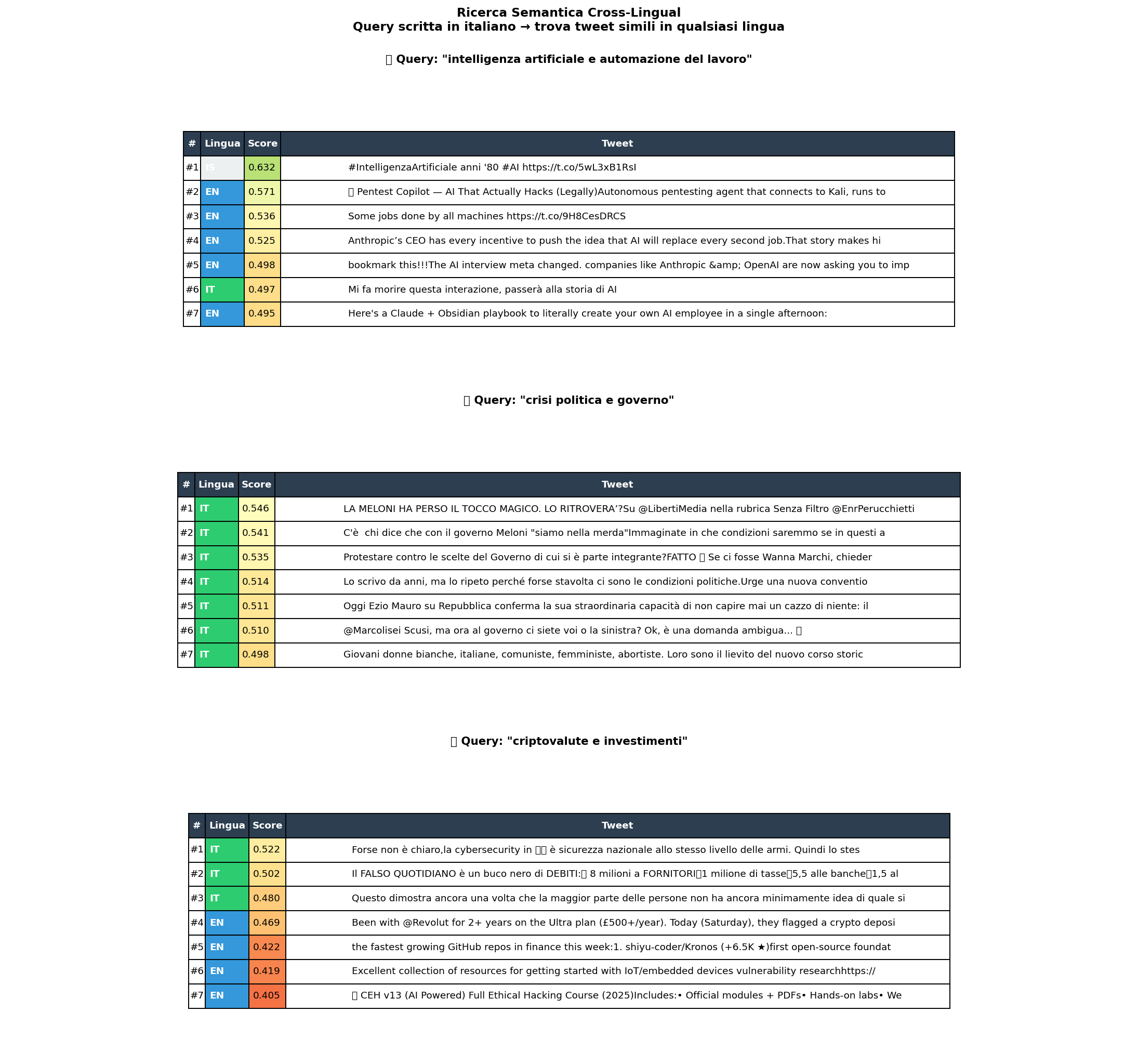
Quando X ti mostra un tweet in cinese che non hai cercato, in una lingua che non capisci, sta navigando uno spazio geometrico dove quel tweet è vicino a quello che ti interessa. La traduzione automatica è solo la didascalia.
// Da 384 a 2 Dimensioni
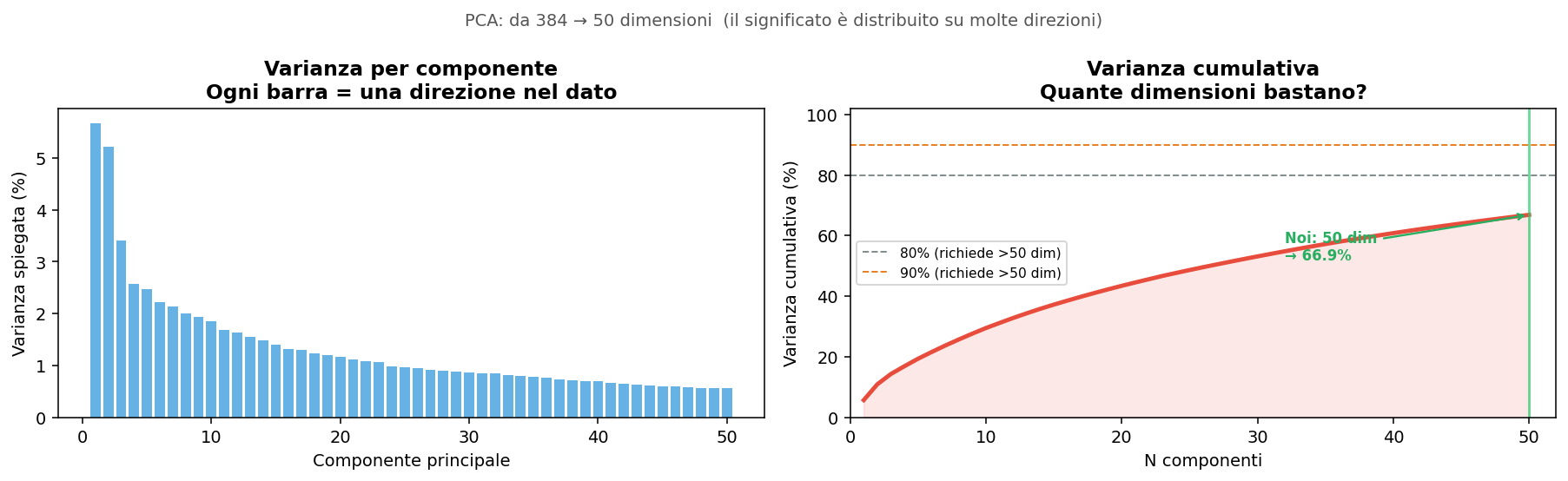
Sezione 05. Come si visualizza l'invisibile384 dimensioni non si disegnano su uno schermo. Per visualizzare la struttura dello spazio ho usato due tecniche di riduzione dimensionale in sequenza.
Proiezione lineare. Conserva il 66.85% della varianza totale. Elimina il rumore, mantiene la struttura principale. Veloce e stabile.
Riduzione non lineare. Preserva sia la struttura locale (vicini restano vicini) sia quella globale (cluster lontani restano lontani).
Proiezione finale per la visualizzazione. A questo punto ogni tweet è un punto su un piano che possiamo guardare.
Il risultato è una mappa. Ogni punto è un tweet. I punti vicini hanno significato simile, indipendentemente dalla lingua con cui sono stati scritti.
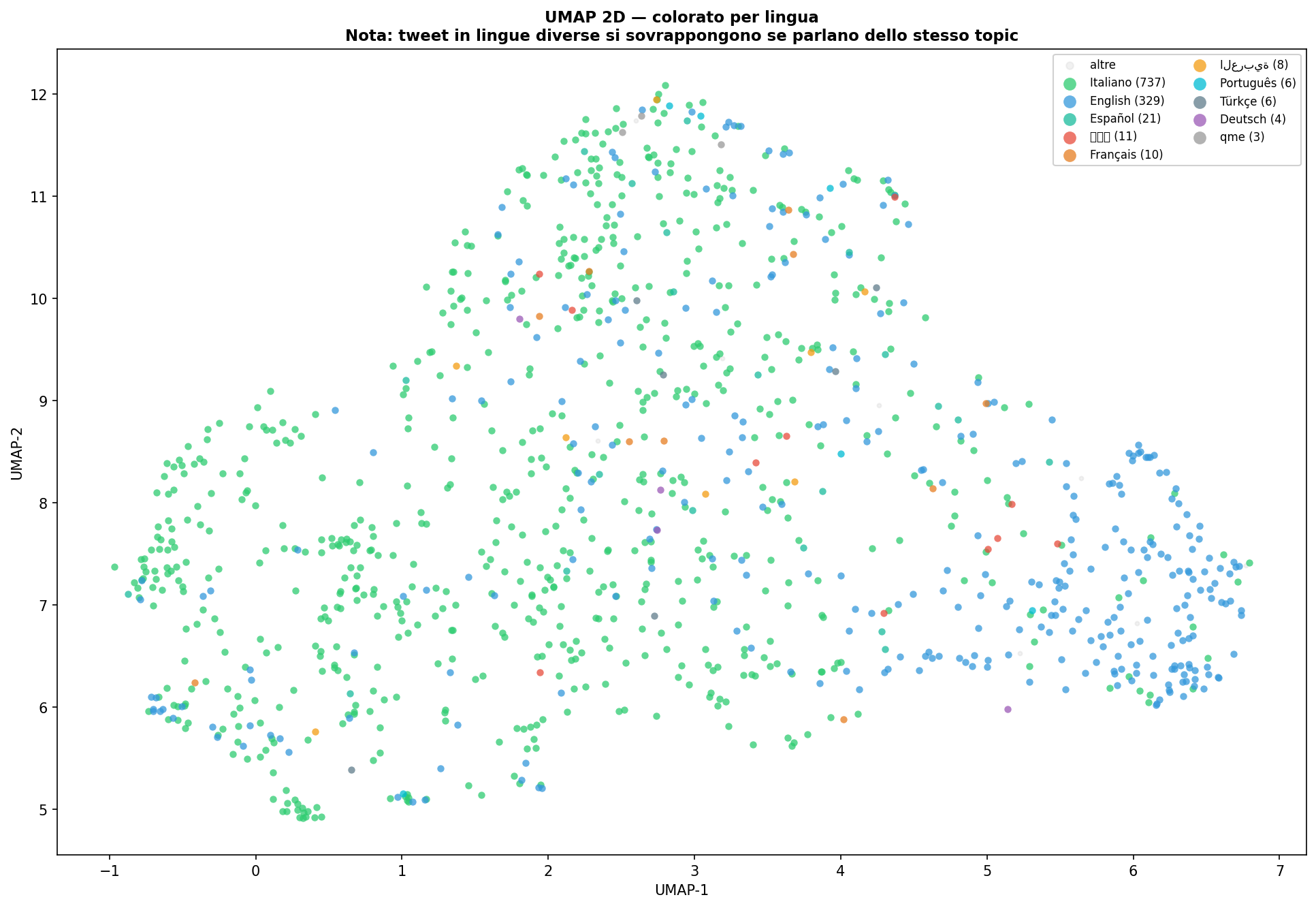
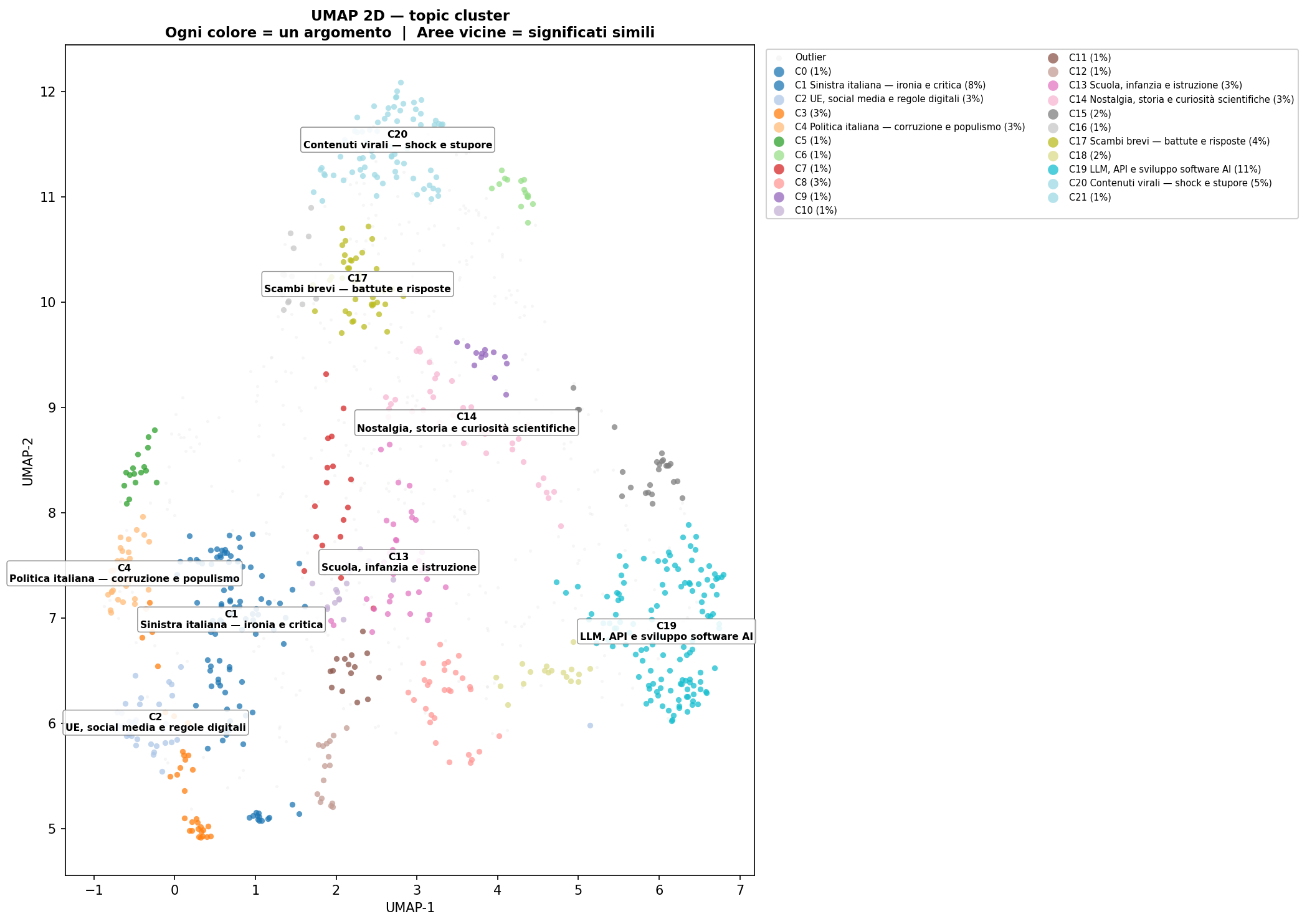
Guardali uno accanto all'altro. A sinistra le lingue, a destra i cluster. Le lingue sono mescolate dentro ogni cluster. Italiano, inglese, arabo, cinese: stessa zona dello spazio, stesso argomento. Il raggruppamento non segue la lingua, segue il significato.
Nota metodologica. UMAP preserva bene le relazioni locali tra punti vicini, ma distorce quelle globali: le distanze assolute tra cluster lontani sulla mappa non sono proporzionali alle distanze reali nello spazio a 384 dimensioni. Le strutture visibili vanno interpretate come approssimazioni della geometria originale, non come misure precise.
// I Cluster del Mio Feed
Sezione 06. Cosa ha trovato l'algoritmoPer trovare i gruppi ho usato HDBSCAN: un algoritmo di clustering che non richiede di specificare quanti cluster vuoi. Li trova da solo, basandosi sulla densità locale dei punti. Se una zona dello spazio è densa, è un cluster. Se un punto è isolato, è un outlier.
Risultato: 22 cluster, 433 outlier. I cluster non sono costruzioni mie: sono la struttura naturale del mio feed, estratta dallo spazio vettoriale.
Le etichette che vedete nei grafici non sono generate da un keyword extractor automatico. Ho letto manualmente i tweet più rappresentativi di ogni cluster, quelli più vicini al centroide geometrico del gruppo, e ho assegnato un nome che descrivesse il tema reale. Alcuni esempi:
Il cluster più grande, quasi l'11% del feed, parla di LLM, API, sviluppo software legato all'AI. In più lingue: inglese, italiano, cinese. Stesso argomento, stessa zona dello spazio, traduzione automatica come optional.
// Quanto È Mainstream il Tuo Feed
Sezione 07. Densità locale e livelli cognitiviC'è un'altra cosa che si può misurare nello spazio vettoriale: la densità locale. Se un tweet è in una zona densa, circondato da molti vicini, significa che parla di un argomento comune, molto dibattuto. Se è in una zona rada, parla di qualcosa di niché.
Ho usato KNN (k-nearest neighbors) per misurare la densità intorno a ogni punto e ho diviso il feed in tre livelli:
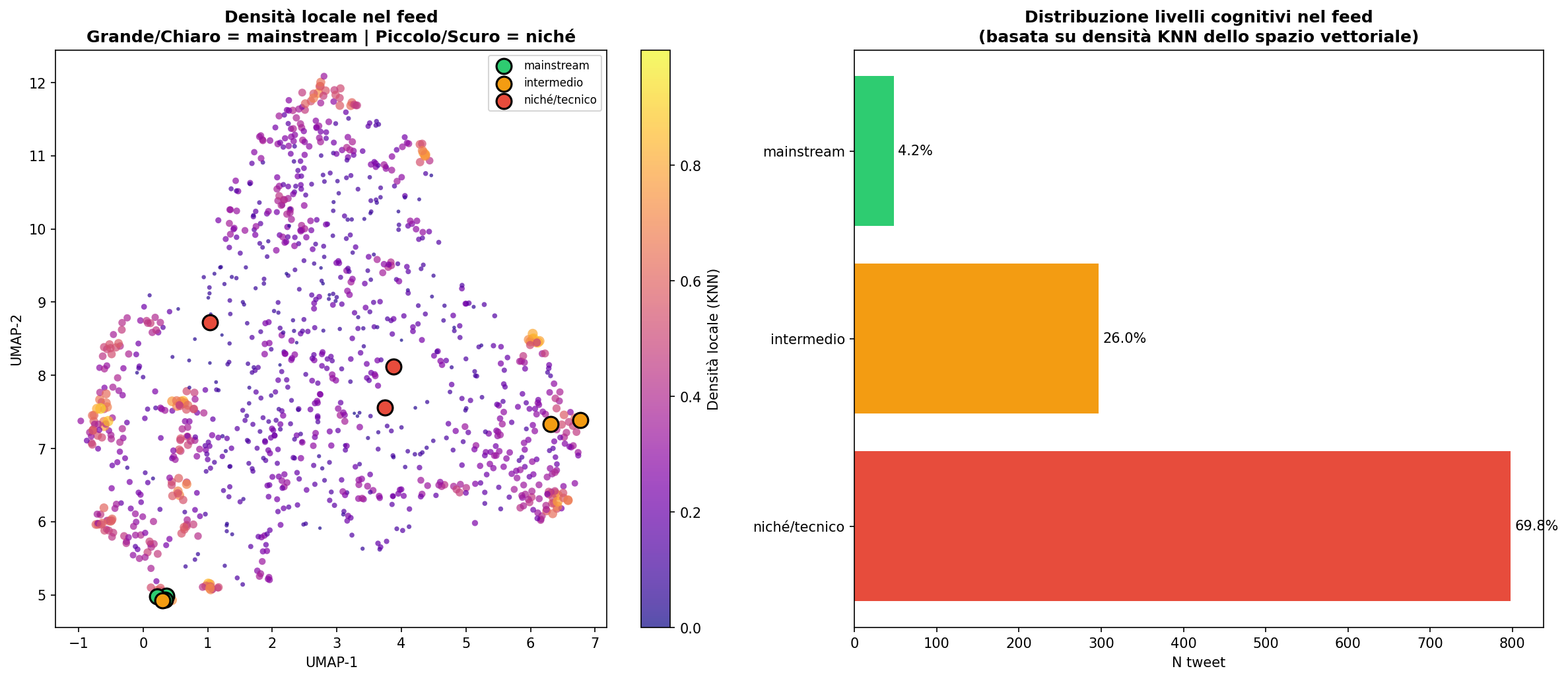
Il 70% del mio feed è in zone a bassa densità. Argomenti specialistici, poco condivisi in termini assoluti. Solo il 4% è mainstream. Questo mi dice dove mi trovo sulla mappa, rispetto alla popolazione totale dei tweet: lontano dal centro.
// Il Tuo Profilo Algoritmico
Sezione 08. Cosa pensa di te l'algoritmoL'ultima cosa che ho costruito è un grafico che risponde alla domanda originale della iena in modo diretto: cosa pensa di te l'algoritmo di X?
Non le preferenze che hai dichiarato, gli interessi che hai scelto di seguire. La struttura di quello che il sistema ha deciso di mostrarti. Ogni cluster, con il suo peso percentuale, è una coordinata: dove il sistema di raccomandazione ti ha messo sulla mappa.
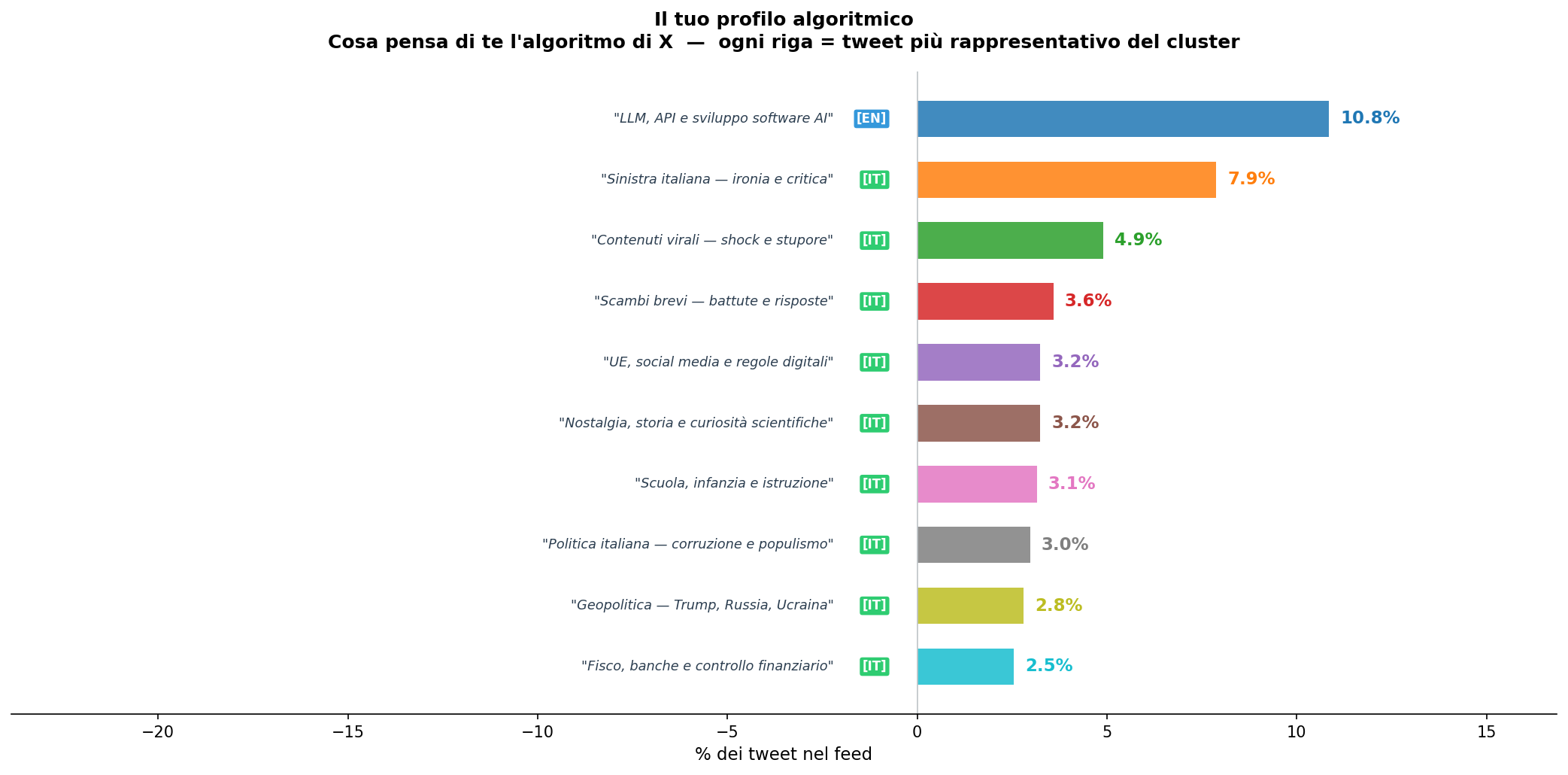
Attenzione. Quello che vedi è il profilo che X ha costruito su di te, basato su quello che ti ha mostrato, che può coincidere con i tuoi interessi reali o no. Il feed non è tuo, come abbiamo già visto. Adesso però hai la mappa.
// Il Test Falsificabile
Sezione 09. Se è vero, allora succede questoUn'affermazione vale quanto riesci a falsificarla. Quindi: se il modello cattura davvero il significato indipendentemente dalla lingua, allora un tweet in italiano su AI deve essere più vicino a un tweet in inglese su AI che a un tweet in italiano su un argomento completamente diverso.
Ho preso tre tweet reali dal feed:
"Troppo potente e troppo rischioso, per essere messo nelle mani di tutti. Il nuovo modello AI di Anthropic che ha mandato nel panico le istituzioni..."
"I think this is the coolest thing ever, cross-SIEM Sysmon <-> CloudTrail correlation - coming soon to AI Cyber Defense Ops!"
"Confusione a Teheran, caos a Hormuz, propaganda al massimo. Trump ha parlato di un accordo imminente..."
A vs C (stessa lingua, topic opposto) = 0.162
Un tweet in italiano sull'AI è 2.7x più vicino a un tweet in inglese sull'AI che a un tweet in italiano sulla guerra
Il test regge. La lingua conta meno dell'argomento. Quei numeri lo dimostrano.
// La Mappa Numerica del Feed
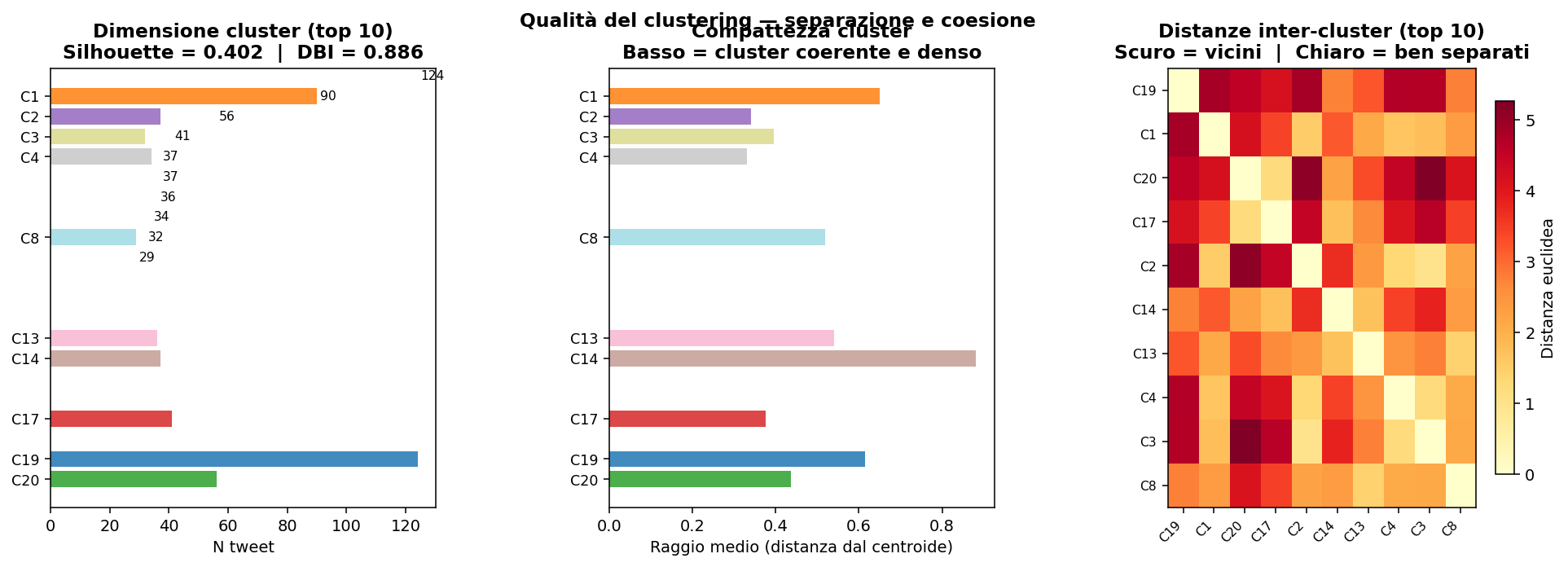
Sezione 10. Cluster, distanze, densitàI cluster non sono solo etichette. Hanno una geometria misurabile: quanto sono compatti, quanto sono densi, quanto pesano sul feed totale. Questa è la tabella completa.
| Cluster | Argomento | Tweet | % Feed | Dist. media | Densità |
|---|---|---|---|---|---|
| C19 | LLM, API e sviluppo software AI | 124 | 10.8% | 0.520 | 0.4 |
| C1 | Sinistra italiana, ironia e critica | 90 | 7.9% | 0.436 | 0.4 |
| C20 | Contenuti virali, shock e stupore | 56 | 4.9% | 0.355 | 0.4 |
| C17 | Scambi brevi, battute e risposte | 41 | 3.6% | 0.327 | 0.3 |
| C14 | Nostalgia, storia e curiosità scientifiche | 37 | 3.2% | 0.516 | 0.2 |
| C2 | UE, social media e regole digitali | 37 | 3.2% | 0.389 | 0.4 |
| C13 | Scuola, infanzia e istruzione | 36 | 3.1% | 0.433 | 0.3 |
| C4 | Politica italiana, corruzione e populismo | 34 | 3.0% | 0.306 | 0.5 |
| C3 | Geopolitica, Trump, Russia, Ucraina | 32 | 2.8% | 0.321 | 0.5 |
| C8 | Fisco, banche e controllo finanziario | 29 | 2.5% | 0.452 | 0.2 |
| C15 | Claude, AI tools e produttività tech | 26 | 2.3% | 0.468 | 0.5 |
| C18 | Cybersecurity, CVE e lavoro in tech | 18 | 1.6% | 0.474 | 0.3 |
| C7 | Cinismo e disillusione sociale | 17 | 1.5% | 0.359 | 0.2 |
| C5 | Roma vs Milano, rivalità urbana | 16 | 1.4% | 0.281 | 0.5 |
| C21 | Cultura, linguaggio e critica letteraria | 16 | 1.4% | 0.250 | 0.3 |
| C12 | Giornalismo, propaganda e disinformazione | 16 | 1.4% | 0.365 | 0.3 |
| C16 | Commenti ironici e battute sul web | 14 | 1.2% | 0.288 | 0.3 |
| C0 | Iran vs USA, guerra e propaganda | 13 | 1.1% | 0.290 | 0.5 |
| C9 | AI-generated images e creatività visiva | 13 | 1.1% | 0.341 | 0.3 |
| C10 | Diritto, giustizia e riforme istituzionali | 15 | 1.3% | 0.441 | 0.2 |
| C11 | Immigrazione, toni accesi e polemiche | 15 | 1.3% | 0.303 | 0.2 |
| C6 | Momenti di vita quotidiana e ironia | 15 | 1.3% | 0.350 | 0.5 |
Come leggere la tabella. "Dist. media" è la distanza coseno media tra ogni tweet e il centroide del suo cluster: più è bassa, più il cluster è coeso e specifico. C21 (cultura/linguaggio, 0.250) e C5 (Roma vs Milano, 0.281) sono i più compatti. C19 (LLM/AI, 0.520) e C14 (nostalgia/storia, 0.516) sono i più dispersi: argomenti ampi con molte sfumature. "Densità" misura quanto i tweet sono semanticamente simili tra loro nello spazio locale. Cluster densi indicano argomenti trattati in modo uniforme; cluster meno densi indicano temi più vari e sfaccettati.
// La Lettura da Hacker
Sezione 09. Cosa ci vedi se sai guardareLa maggior parte delle persone leggerà questa notizia e penserà: hanno aggiunto la traduzione, comodo. Fine.
Quello che X ha attivato è un layer di normalizzazione. Tutto il contenuto che entra nel feed, qualsiasi lingua, qualsiasi formato, qualsiasi cultura, viene proiettato in uno spazio unico e condiviso. Da quel momento in poi è tutto confrontabile. Rankabile. Ottimizzabile.
↓ embedding multilingue
output: vettori confrontabili nello stesso spazio
lingua = accidente superficiale · significato = coordinate geometriche
Questo cambia qualcosa per chi sa usarlo. Se il tuo feed non ha più barriere linguistiche a livello di algoritmo, puoi smettere di pensare "seguo persone italiane" e iniziare a pensare "intercetto segnali su certi argomenti, ovunque arrivino".
Un argomento esplode prima in inglese o in cinese. Prima arrivava nel tuo feed italiano con settimane di ritardo, filtrato dai media. Ora arriva direttamente, tradotto in tempo reale.
Giornali e newsletter sono layer di ritardo e filtraggio. Il segnale originale esiste già nello spazio semantico globale. Ora puoi toccarlo direttamente.
Lo stesso evento raccontato da prospettive diverse finisce vicino nello spazio vettoriale. Puoi vedere in un colpo come lo stesso fatto viene inquadrato in lingue e culture diverse.
I segnali deboli sono quasi sempre in nicchie linguistiche che non segui. Ora l'algoritmo te li porta comunque: la traduzione li rende leggibili. Il rumore di fondo diventa ricercabile.
Rovescio della medaglia. Lo stesso layer che ti porta segnali utili porta anche propaganda, disinformazione e contenuti ottimizzati per engagement da qualsiasi angolo del mondo, già tradotti e già nel tuo feed. La normalizzazione è simmetrica: non distingue tra segnale e rumore. Quello lo devi fare tu.
Il limite: quando il sarcasmo diventa rumore
C'è un caso in cui il sistema si inceppa: il sarcasmo.
Prendi questo tweet italiano reale dal feed:
In italiano il significato è chiarissimo: è ironia feroce contro il governo. Ma un modello di embedding lavora sulla superficie semantica del testo. Le parole "ottimo", "complimenti", "bravi" hanno un vettore positivo. Il tono critico reale viene parzialmente perso.
La traduzione automatica peggiora le cose: Grok traduce correttamente le parole, ma il sarcasmo implicito in quella costruzione italiana specifica può non sopravvivere in inglese. Il tweet finisce vicino a contenuti genuinamente positivi sul governo, non a contenuti critici.
Il modello non capisce il registro. Capisce le parole. Per argomenti fattuali funziona benissimo: AI, guerra, politica estera, tecnologia. Per ironia, sarcasmo, doppi sensi culturali: attenzione.
// Replicalo
Lab. Due script, un terminaleTutto il codice è su GitHub, nella cartella scripts/vicino-vuol-dire-vettore/. Puoi replicare l'analisi sul tuo feed in meno di 10 minuti.
pip install -r requirements.txt
python 00_extract.py — legge da SnareData.twitter e salva in data/tweets.json
python 01_analisi.py — embedding, riduzione, clustering, 10 grafici, report JSON
| File | Cosa fa | Output |
|---|---|---|
00_extract.py | Estrae tweet da MongoDB, filtra promossi e duplicati | data/tweets.json |
01_analisi.py | Embedding multilingue, PCA, UMAP, HDBSCAN, 10 grafici, report | output/*.png, output/report.json, output/tweets_full.csv |
output/cluster_labels.json | Etichette manuali per i cluster — modificabile a piacere | Letto da 01_analisi.py se presente |
Struttura cartelle.
vicino-vuol-dire-vettore/
├── 00_extract.py
├── 01_analisi.py
├── requirements.txt
├── data/
│ └── tweets.json ← il tuo feed
└── output/
├── 01_tweet_come_vettore.png
├── 02_crosslingual_heatmap.png
├── ...
├── cluster_labels.json ← etichette cluster (opzionale)
├── report.json
└── tweets_full.csv
Se non hai MongoDB, puoi partire direttamente da un tweets.json tuo con la struttura [{"text": "...", "lang": "it", "created_at": "..."}]. Lo script 00_extract.py serve solo per chi cattura il feed con Snare.
// Chiudiamo il Cerchio
Sezione 10. La risposta alla ienaEro rimasto a quella domanda: "vicine come?"
La risposta è questa. Ogni tweet che leggi è stato trasformato in 384 numeri. Quei numeri definiscono la sua posizione in uno spazio matematico. La distanza in quello spazio misura la somiglianza semantica: non lessicale, non grammaticale. Il significato. Il significato. Quello che resta quando togli la lingua.
X ha tolto il filtro linguistico sull'output. Il motore di raccomandazione girava già su vettori cross-lingual, già cieco alle lingue, già capace di trovare un tweet in giapponese rilevante per un italiano. Ma lo tratteneva. Ora non lo trattiene più, e Grok lo traduce in tempo reale così non devi nemmeno cambiare tab.
La risposta non è "perché X sa che ti interessa". La risposta è che quel tweet, trasformato in 384 numeri, si trovava nelle vicinanze del tuo profilo nello spazio semantico. Il motore lo sapeva già prima. Adesso ti arriva anche.
Il mondo non è diventato più piccolo perché ci capiamo meglio. È diventato più piccolo perché hanno rimosso il tappo che teneva fuori tutto quello che il modello aveva già deciso che ti apparteneva.
La iena, quando le ho spiegato tutto questo, ha detto: "Quindi mi spiano."
"No, misurano."
"Stessa cosa."
Non ho risposto. Aveva ragione.
Il motore era già lì.
Hanno tolto il freno.
Ora esce tutto.
1.143 tweet · 22 lingue · 22 cluster · silhouette 0.402
Catturato il 19 aprile 2026, prima dell'annuncio ·
github.com/pinperepette